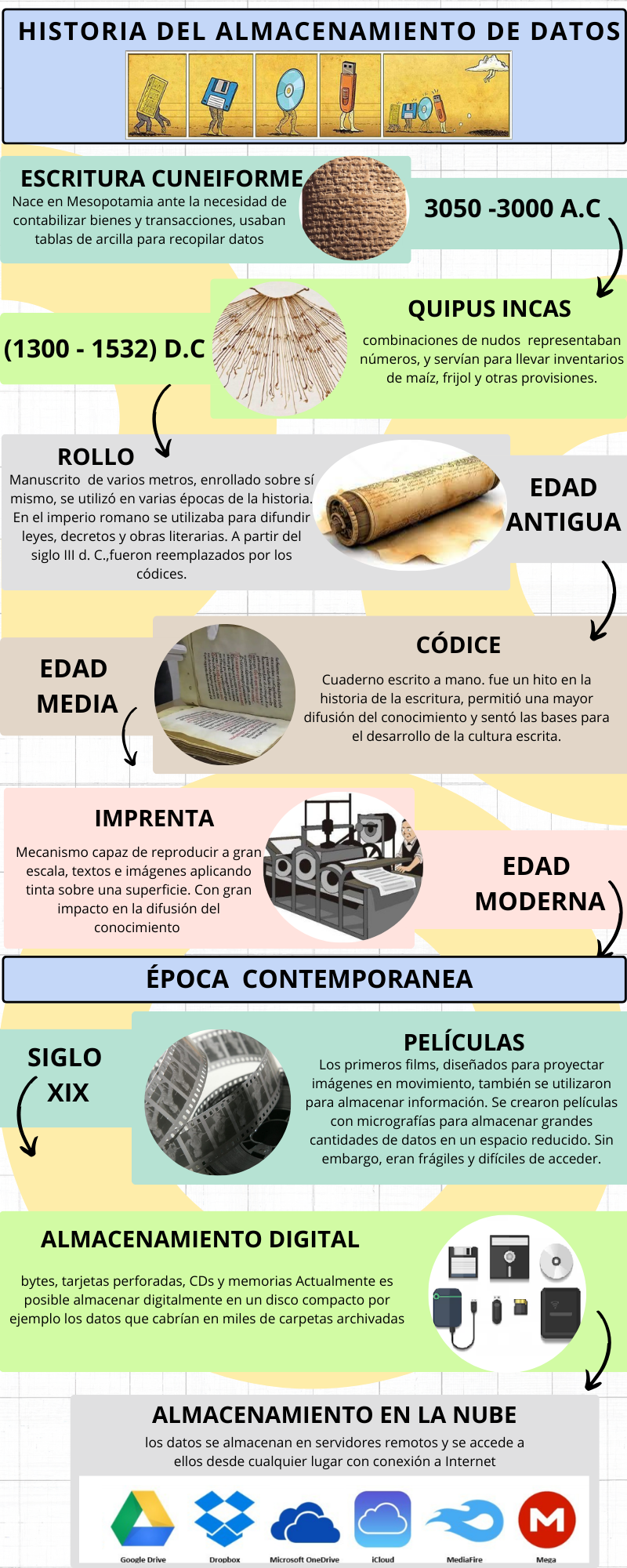
Análisis exploratorio de datos
Historia de la estadística
Graficamente
.jpg)
¿Qué es la estadística?
Ciencia que describe y realiza inferencias sobre el mundo desde una muestra de datos
Ciencia que proporciona metodologías para recolectar organizar, resumir, presentar y analizar datos y hacer inferencias a partir de ellos.
Ramas de la estadística
| Estadística | Definción |
|---|---|
| Descriptiva | Organiza y describe las características de un conjunto de datos con el propósito de facilitar su aplicación, |
Estadística descriptiva:
Los parámetros estadísticos usados son las medidas de tendencia central y de variabilidad, y los gráficos de barras, de tortas y el histograma.
Estadística inferencial:
Obtiene conclusiones de la población partiendo de una muestra, por medio de diferentes métodos, como las puebas de hipótesis, pronósticos de futuras observaciones, correlaciones y modelos de asociación entre variables.
Enfoques de la estadística

Algunas definiciones
Población: Conjunto de elementos sobre los que queremos hacer afirmaciones
Muestra: Conjunto de personas o cosas que se consideran representativos del grupo al que pertenecen, con la finalidad de estudiar o determinar las características del grupo.
Parámetro: Valor descriptivo de la población
Estadístico: Valor descriptivo para una muestra
Base de datos: Colección de información organizada, de tal modo que sea fácilmente accesible, gestionada y actualizada
Almacenamiento de bases de datos
Punto atípico o outlier Son observaciones extremas, alejadas hacia valores muy grandes o pequeños comparadas con el resto de valores. Los valores atípicos pueden ser indicativos de datos que pertenecen a una población diferente del resto de las muestras establecidas. Se pueden detectar con un análisis descriptivo, mediante diagramas de dispersión, boxplot o histograma.

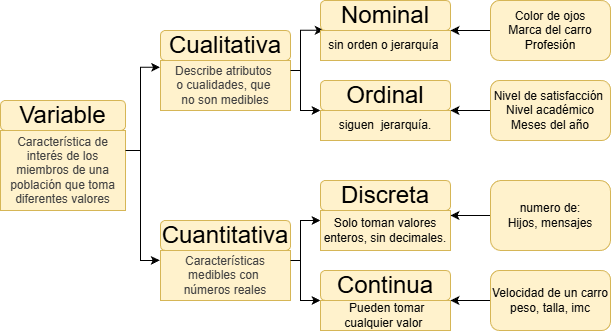
Tipos de variables
Característica o condición que puede tomar diferentes valores en una muestra. Ejm:
- Presión sanguínea
- Masa de los niños
- Frecuencia cardiaca
- Estatura de un grupo de estudiantes
- Edad de los pacientes de un médico
Tipos de variables
Actividad
Clasifique las siguiente variables según sea el caso
| variable | tipo de variable | clasificación | niveles |
|---|---|---|---|
| Color de ojos | Cualitativa | Nominal | verde, azul,cafe |
| Edad | |||
| velocidad | |||
| Estado civil | |||
| Color de la piel | |||
| Color del cabello | |||
| Marcas de carro | |||
| Número de hijos de una familia | |||
| Número de mensajes enviados por whatsap un dia | |||
| Número de estudiantes conectados a clase | |||
| Días de la semana |
Frecuencia estadística
La frecuencia es el número de veces en que un evento se repite durante un experimento, comúnmente, la distribución de la frecuencia suele visualizarse con el uso de histogramas.
Frecuencia absoluta
Es el conteo o número de veces que sucede un evento en un experimento
Frecuencia relativa
Es el porcentaje o proporción de veces que sucede un evento en un experimento, se calcula así:
\[X_i=\frac{xi}{N}=\frac{veces\quad que \quad se \quad observa \quad un \quad evento }{Total \quad de \quad veces}\]
Tablas de frecuencia
Se pueden construir tablas de frecuencia para variables cualitativas y cuantitativas, con la frecuencia absoluta y la frecuencia relativa.
Ejemplo:
Tablas de frecuencia en R
Se preguntó a los estudiantes sobre el hábito de fumar y el género, los resultados encontrados se ilustran a continuación
#Para instalar librerías se hace uso de la siguiente #instrucción, sin el #
#El # sirve para marcar comentarios en códigos de R
#install.packages("knitr")
library(knitr)
fuma <- c('NUNCA','1 ó 2 VECES','NUNCA','NUNCA','CADA MES','NUNCA','NUNCA','NUNCA','A DIARIO', 'NUNCA', 'NUNCA','A DIARIO','1 ó 2 VECES', 'NUNCA', 'NUNCA', 'NUNCA','CADA MES','A DIARIO', 'NUNCA','A DIARIO', 'NUNCA','NUNCA', 'NUNCA','NUNCA', 'CADA SEMANA', 'NUNCA','NUNCA','CADA SEMANA','1 ó 2 VECES','1 ó 2 VECES','1 ó 2 VECES','1 ó 2 VECES', 'CADA SEMANA', 'NUNCA','NUNCA','NUNCA', 'NUNCA','A DIARIO', 'NUNCA', 'NUNCA','NUNCA','NUNCA','NUNCA','NUNCA','NUNCA','CADA MES','1 ó 2 VECES','A DIARIO','NUNCA','CADA SEMANA', 'NUNCA','NUNCA', 'NUNCA','1 ó 2 VECES','A DIARIO', 'CADA MES','A DIARIO','NUNCA','NUNCA','1 ó 2 VECES', '1 ó 2 VECES','1 ó 2 VECES','1 ó 2 VECES','CADA SEMANA', 'NUNCA','NUNCA','1 ó 2 VECES','CADA SEMANA','NUNCA','1 ó 2 VECES','1 ó 2 VECES', 'NUNCA','1 ó 2 VECES','1 ó 2 VECES','1 ó 2 VECES','NUNCA','NUNCA','NUNCA','NUNCA','NUNCA','NUNCA','NUNCA','NUNCA','NUNCA','1 ó 2 VECES','NUNCA', 'NUNCA', 'NUNCA','1 ó 2 VECES','NUNCA','CADA SEMANA','1 ó 2 VECES','1 ó 2 VECES','1 ó 2 VECES','A DIARIO','CADA MES','1 ó 2 VECES','CADA SEMANA', 'NUNCA', 'NUNCA','A DIARIO','1 ó 2 VECES','CADA SEMANA','NUNCA','1 ó 2 VECES','NUNCA','1 ó 2 VECES','NUNCA','NUNCA','NUNCA','NUNCA','CADA MES','CADA SEMANA','NUNCA','1 ó 2 VECES','1 ó 2 VECES','NUNCA','NUNCA','NUNCA','CADA MES','1 ó 2 VECES','NUNCA','NUNCA','NUNCA','1 ó 2 VECES', 'NUNCA','NUNCA','A DIARIO','NUNCA','A DIARIO','A DIARIO','CADA MES','1 ó 2 VECES','NUNCA','CADA MES', 'NUNCA','NUNCA','NUNCA','NUNCA','1 ó 2 VECES','1 ó 2 VECES','NUNCA','NUNCA','NUNCA','CADA MES','1 ó 2 VECES')
# Tabla de resumen
tabla=table(fuma)
tabla## fuma
## 1 ó 2 VECES A DIARIO CADA MES CADA SEMANA NUNCA
## 35 13 10 10 78#Añadir totales
Tab=addmargins(tabla)
Tab## fuma
## 1 ó 2 VECES A DIARIO CADA MES CADA SEMANA NUNCA Sum
## 35 13 10 10 78 146# Tabla de proporciones o porcentajes
Tab1=prop.table(table(fuma))
Tab1## fuma
## 1 ó 2 VECES A DIARIO CADA MES CADA SEMANA NUNCA
## 0.23972603 0.08904110 0.06849315 0.06849315 0.53424658#Añador totales
Tab2=addmargins(Tab1)
Tab2## fuma
## 1 ó 2 VECES A DIARIO CADA MES CADA SEMANA NUNCA Sum
## 0.23972603 0.08904110 0.06849315 0.06849315 0.53424658 1.00000000gen=c('Hombre','Hombre','Hombre','Hombre','Hombre','Hombre','Hombre','Hombre','Hombre','Hombre','Hombre','Hombre','Mujer','Mujer','Mujer','Hombre','Hombre','Mujer','Mujer','Hombre','Mujer','Mujer','Hombre','Mujer','Hombre','Mujer','Hombre','Mujer','Mujer','Hombre','Hombre','Mujer','Mujer','Mujer','Mujer','Mujer','Mujer','Hombre','Hombre','Hombre','Hombre','Hombre','Mujer','Hombre','Hombre','Hombre','Mujer','Hombre','Mujer','Hombre','Mujer','Hombre','Mujer','Mujer','Mujer','Mujer','Hombre','Mujer','Hombre','Hombre','Hombre','Mujer','Hombre','Hombre','Hombre','Mujer','Hombre','Mujer','Mujer','Hombre','Hombre','Hombre','Mujer','Mujer','Mujer','Mujer','Hombre','Hombre','Hombre','Mujer','Hombre','Hombre','Hombre','Hombre','Hombre','Mujer','Mujer','Mujer','Mujer','Hombre','Mujer','Hombre','Mujer','Hombre','Hombre','Hombre','Hombre','Mujer','Hombre','Hombre','Hombre','Mujer','Hombre','Hombre','Hombre','Hombre','Hombre','Hombre','Hombre','Hombre','Hombre','Hombre','Hombre','Hombre','Hombre','Hombre','Hombre','Hombre','Hombre','Hombre','Hombre','Hombre','Mujer','Hombre','Hombre','Mujer','Hombre','Hombre','Mujer','Mujer','Hombre','Mujer','Hombre','Mujer','Mujer','Hombre','Mujer','Hombre','Hombre','Hombre','Mujer','Mujer','Hombre','Hombre','Hombre','Hombre')
# Tabla de resumen
table(gen)## gen
## Hombre Mujer
## 93 53#añadir totales
addmargins(table(gen))## gen
## Hombre Mujer Sum
## 93 53 146# Tabla de proporciones o porcentajes
addmargins(prop.table(table(gen)))## gen
## Hombre Mujer Sum
## 0.6369863 0.3630137 1.0000000Pregunta ¿Quién fuma con más frecuencia? Hombres o mujeres
Tablas de contingencia
Además de las tablas de frecuencia también podemos encontrar tablas de doble entrada o tablas de contingencia, donde se pueden relacionar dos variables cualitativas, con sus diferentes niveles. Además de usar la frecuencia absoluta, la frecuencia relativa puede usarse de diferentes maneras
Ejemplo 1
Se analiza el hobbie (Bailar, Ver TV, Deporte) y el género (Femenino y masculino) y se realiza una tabla de doble entrada:
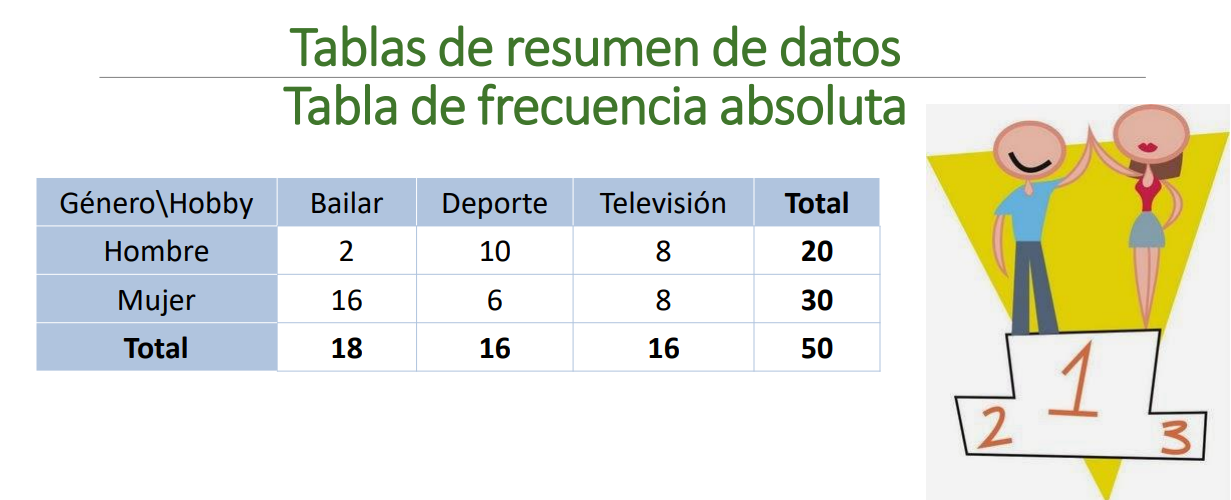
Tabla de contingencia
Esta tabla tiene varias formas posibles de ser analizada
Tabla de frecuencia relativa total
Cada observación se divide por el número total.
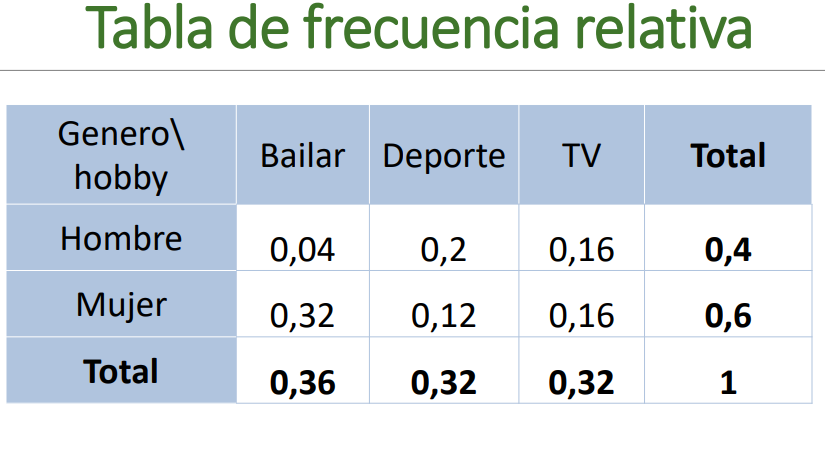
Tabla de contingencia relativa
Tabla de frecuencia relativa por filas
Cada observación se divide por el total de la fila, esta forma sirve para comparar, en este caso, cuál es el deporte favorito de cada genero.
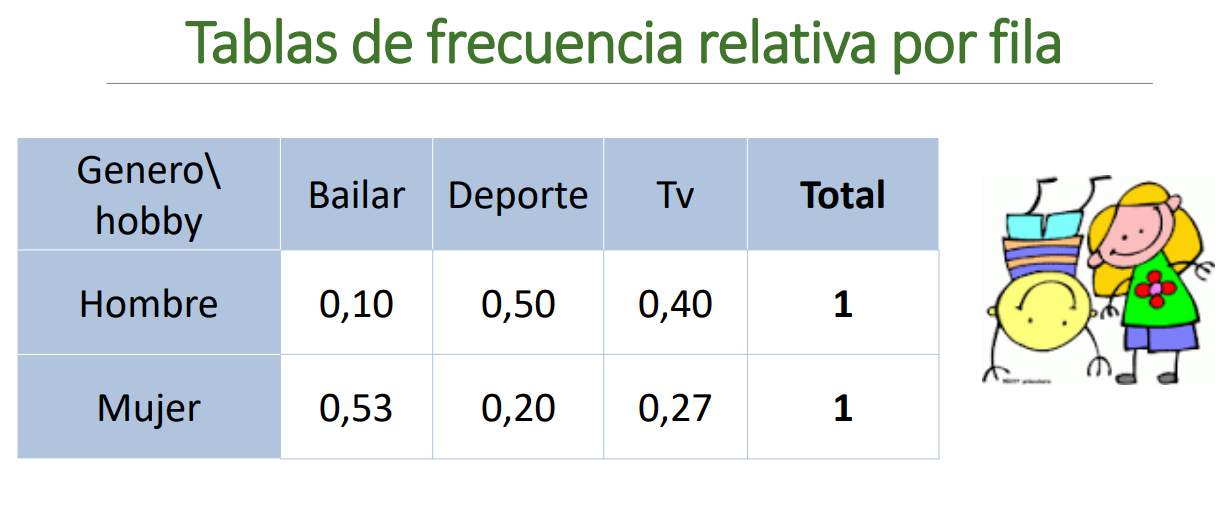
Tabla de contingencia relativa por filas
Tabla de frecuencia relativa por columnas
Cada observación se divide por el total de la columna, esta forma sirve para comparar, en este caso, cuál género prefiere cada uno de los deportes.
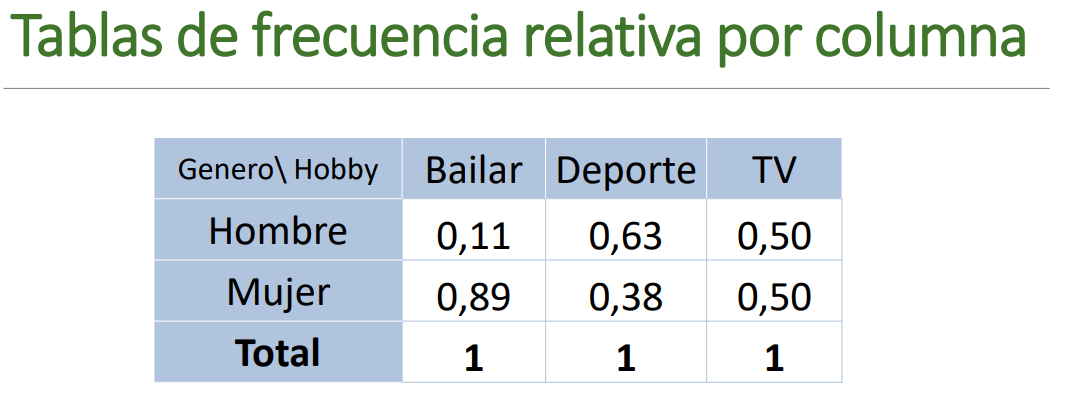
Tabla de contingencia relativa por columnas
Ejemplo 2 La respuesta a la pregunta anterior la podemos encontrar realizando una tabla de contingencia o tabla de doble entrada
#tabla de frecuencia absoluta
marco=table(fuma,gen)
marco## gen
## fuma Hombre Mujer
## 1 ó 2 VECES 22 13
## A DIARIO 10 3
## CADA MES 7 3
## CADA SEMANA 5 5
## NUNCA 49 29##para añadir los totales de filas y columnas
addmargins(marco)## gen
## fuma Hombre Mujer Sum
## 1 ó 2 VECES 22 13 35
## A DIARIO 10 3 13
## CADA MES 7 3 10
## CADA SEMANA 5 5 10
## NUNCA 49 29 78
## Sum 93 53 146Sin embargo con las frecuencias absolutas es difícil visualizar cual de los dos generos fuma con más frecuencia para ello hacemos uso de la frecuencia relativa
## Frecuencia relativa total
marco=table(fuma,gen)
marco2=prop.table(marco)
marco2## gen
## fuma Hombre Mujer
## 1 ó 2 VECES 0.15068493 0.08904110
## A DIARIO 0.06849315 0.02054795
## CADA MES 0.04794521 0.02054795
## CADA SEMANA 0.03424658 0.03424658
## NUNCA 0.33561644 0.19863014##para añadir los totales de filas y columnas
addmargins(marco2)## gen
## fuma Hombre Mujer Sum
## 1 ó 2 VECES 0.15068493 0.08904110 0.23972603
## A DIARIO 0.06849315 0.02054795 0.08904110
## CADA MES 0.04794521 0.02054795 0.06849315
## CADA SEMANA 0.03424658 0.03424658 0.06849315
## NUNCA 0.33561644 0.19863014 0.53424658
## Sum 0.63698630 0.36301370 1.00000000##Frecuencia relativa por filas
tabla3=prop.table(table(fuma,gen),margin=1)
addmargins(tabla3, margin=2)## gen
## fuma Hombre Mujer Sum
## 1 ó 2 VECES 0.6285714 0.3714286 1.0000000
## A DIARIO 0.7692308 0.2307692 1.0000000
## CADA MES 0.7000000 0.3000000 1.0000000
## CADA SEMANA 0.5000000 0.5000000 1.0000000
## NUNCA 0.6282051 0.3717949 1.0000000##Frecuencia relativa por COLUMNAS
tabla4=prop.table(table(fuma,gen),margin=2)
tabla4## gen
## fuma Hombre Mujer
## 1 ó 2 VECES 0.23655914 0.24528302
## A DIARIO 0.10752688 0.05660377
## CADA MES 0.07526882 0.05660377
## CADA SEMANA 0.05376344 0.09433962
## NUNCA 0.52688172 0.54716981addmargins(tabla4, margin=1)## gen
## fuma Hombre Mujer
## 1 ó 2 VECES 0.23655914 0.24528302
## A DIARIO 0.10752688 0.05660377
## CADA MES 0.07526882 0.05660377
## CADA SEMANA 0.05376344 0.09433962
## NUNCA 0.52688172 0.54716981
## Sum 1.00000000 1.00000000Video (ver hasta el minuto 9:20, lo siguiente es de probabilidades)
Gráficos
Existen diferentes tipos de gráficos, los cuales ilustran la información contenida en tablas, dentro de los gráficos más usados se encuentran:
Gráfico de barras
Forma de resumir un conjunto de datos por categorías. Muestra los datos usando varias barras de la misma anchura, cada una representa una categoría concreta. La altura de cada barra es proporcional a la suma de los valores de la categoría que representa.
Histograma
Es una representación gráfica de una variable en forma de barras, donde la superficie de cada barra es proporcional a la frecuencia de los valores representados, sirven para obtener una “primera vista” general de la distribución de la muestra, respecto a una característica
Gráfico de tortas
Representación gráfica de una serie de cantidades, consiste en un círculo dividido en varios sectores, cuyo tamaño corresponde con las proporciones de las cantidades. Básicamente, este tipo de gráfico muestra la relación porcentual entre las partes con relación a su conjunto. El área proporcional en grados de la circunferencia se cacula así:
\[Grados=360° * frecuencia\quad relativa=360°* \frac{veces \quad que \quad se \quad repite \quad un \quad evento}{total\quad de \quad veces}\]
Ejemplo
La siguiente información fue reportada en la revista Motor Trend de EE.UU, en el año 1974. contiene el consumo de combustible y 10 aspectos del diseño y rendimiento para 32 automóviles (modelos 1973–74).
A continuación se ilustra un resumen del número de cilindros que cada uno de los automoviles mostró
library(knitr)
library(ggplot2)
#Base de datos
head(mtcars)## mpg cyl disp hp drat wt qsec vs am gear carb
## Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
## Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
## Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
## Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
## Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
## Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1#Creación de tabla de frcuencia absoluta
j=(table(mtcars$cyl))
#creación de porcentajes
x=data.frame(prop.table(j))
porcentajes=x[,2]
#grados proporcionales
grad=porcentajes*360
m=data.frame(table(mtcars$cyl),porcentajes*100,grad)
colnames(m)=c("cilindros","frecuencia absoluta","Porcentaje","grad°")
barplot(j,col='#4168c3',ylab="Frecuencia absoluta", xlab="Número de cilindros")
box()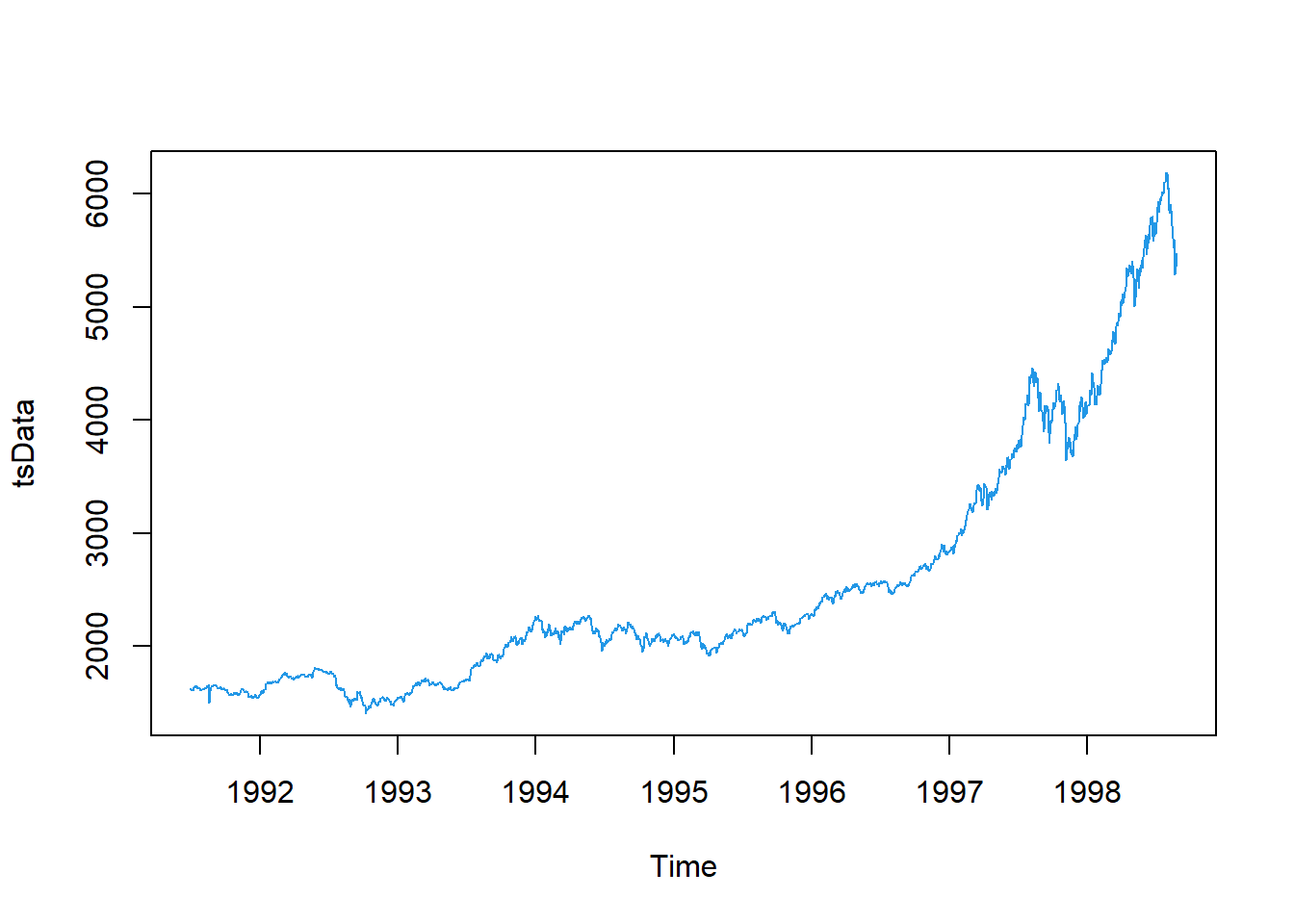
#Gráfico de tortas
bar <- ggplot(data=m, aes(x=1,y= porcentajes,
fill=m$cilindros))+
geom_bar(stat='identity', colour='white') +
coord_polar(theta='y')+
scale_fill_manual(values=c("salmon","steelblue","gray"))+theme_void()+ labs(title="Gráfico de torta")+
geom_text(aes(label=porcentajes*100),
position=position_stack(vjust=0.5),color="white",size=5)
bar## Warning: Use of `m$cilindros` is discouraged.
## ℹ Use `cilindros` instead.
## Use of `m$cilindros` is discouraged.
## ℹ Use `cilindros` instead.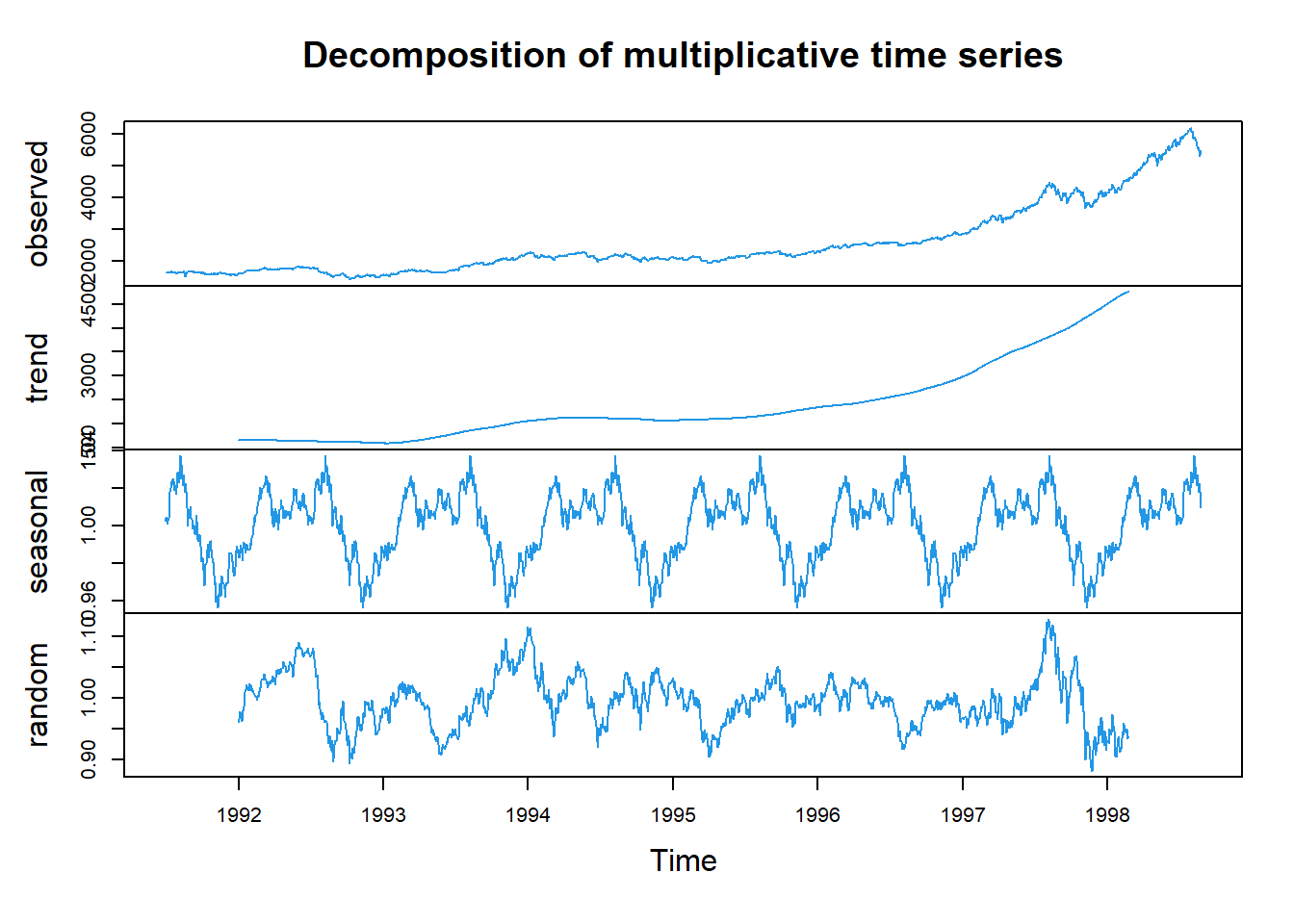
#Gráfico de donas
bar1 <- ggplot(data=m, aes(x=2,y= porcentajes,
fill=m$cilindros))+
geom_bar(stat='identity', colour='white') +
coord_polar(theta='y')+
scale_fill_manual(values=c("salmon","steelblue","gray"))+theme_void()+ labs(title="Gráfico de donas")+xlim(0.5,2.5)+
geom_text(aes(label=porcentajes*100),
position=position_stack(vjust=0.5),color="white",size=5)
bar1## Warning: Use of `m$cilindros` is discouraged.
## ℹ Use `cilindros` instead.
## Use of `m$cilindros` is discouraged.
## ℹ Use `cilindros` instead.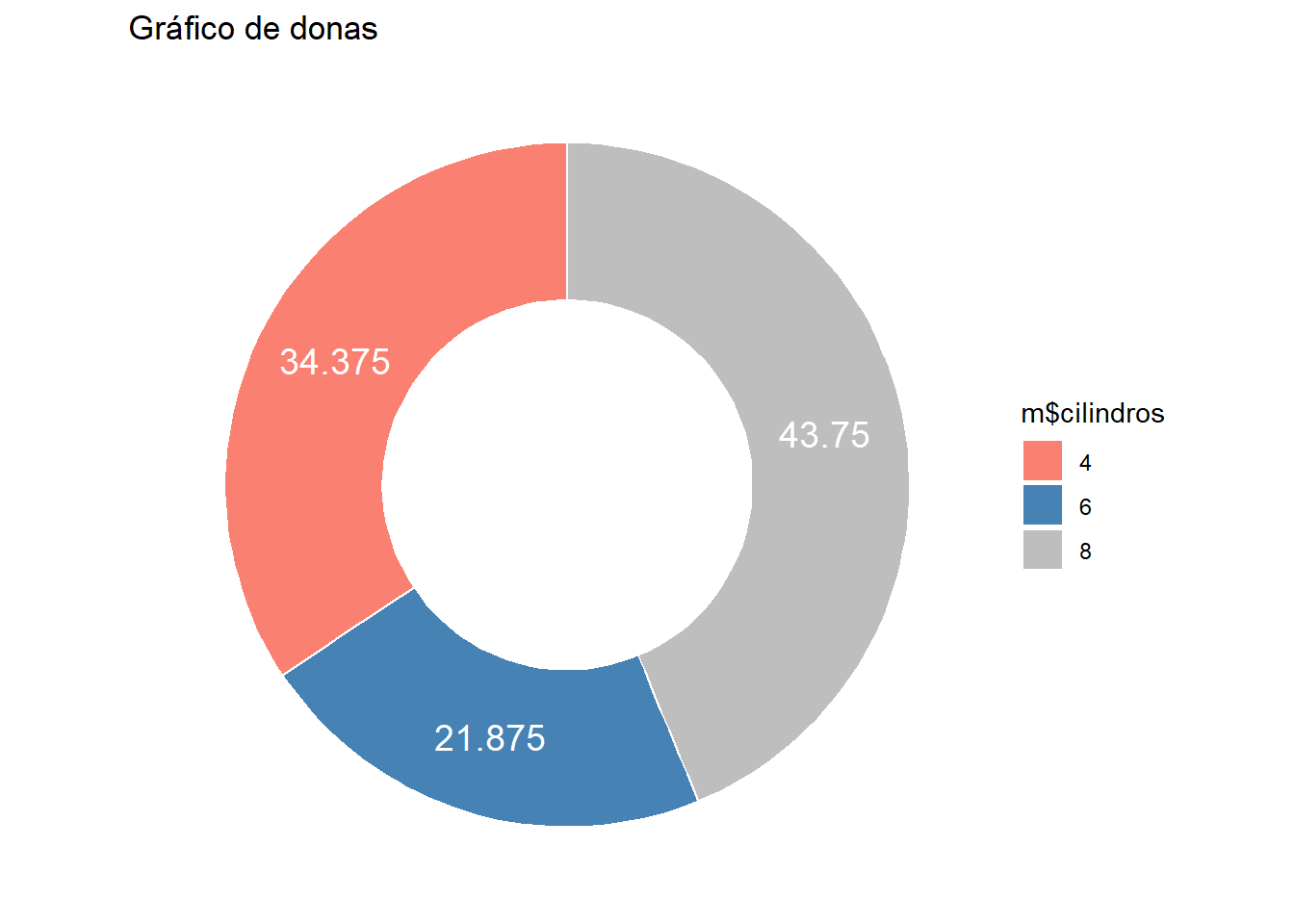
Algunos videos que sirven de ejemplo
Ejemplo 1
Ejemplo 2
Ejemplo 3
En el siguiente ejemplo se hace uso de variables de tipo cualitativo, con la que se construye una tabla de frecuencias, gráfico de barras y de tortas.
Gráfico de series de tiempo
Una serie de tiempo es una colección de observaciones de una variable tomadas de forma secuencial y ordenada en el tiempo (instantes de tiempo equiespacios). Las series pueden tener periodicidad anual, semestral, trimestral, mensual,diaria etc.
Aparecen en numerosos campos
Economía y Marketing
- Precio del alquiler de un apartamento durante varios meses.
— Precio promedio del trigo mensual.
— Índices del precio del petróleo por semana.
Demografía
— Número de habitantes en cierto país por año.
— Tasa de mortalidad infantil por año.
- Infectados por día de COVID19
Medioambiente
— Lluvia recogida diariamente en una localidad.
— Temperatura media diaria.
— Medición diaria de materal particulado en el área metropolitana.
Tendencia
Cambio a largo plazo que se produce en relación al nivel medio, se identifica con un movimiento suave de la serie a largo plazo, puede ser ascendente ó descendente.
Efecto estacional
Variación de un patrón de comportamiento ciclico que se repiten cada cierto periodo de tiempo.
Ejemplo en R
La siguiente base de datos representa los precios de cierre diarios del índice bursátil Alemania DAX (Ibis), desde el año 1991 hasta 1998, los datos se muestrean en horario comercial, es decir, se omiten los fines de semana y feriados. para un total de 1860 observaciones. Los datos fueron proporcionados por Erste Bank AG, Viena, Austria.
La serie de tiempo con su respectiva descomposición se enlistan a continuación.
tsData <- EuStockMarkets[,1] # ts data
plot(tsData,col=4)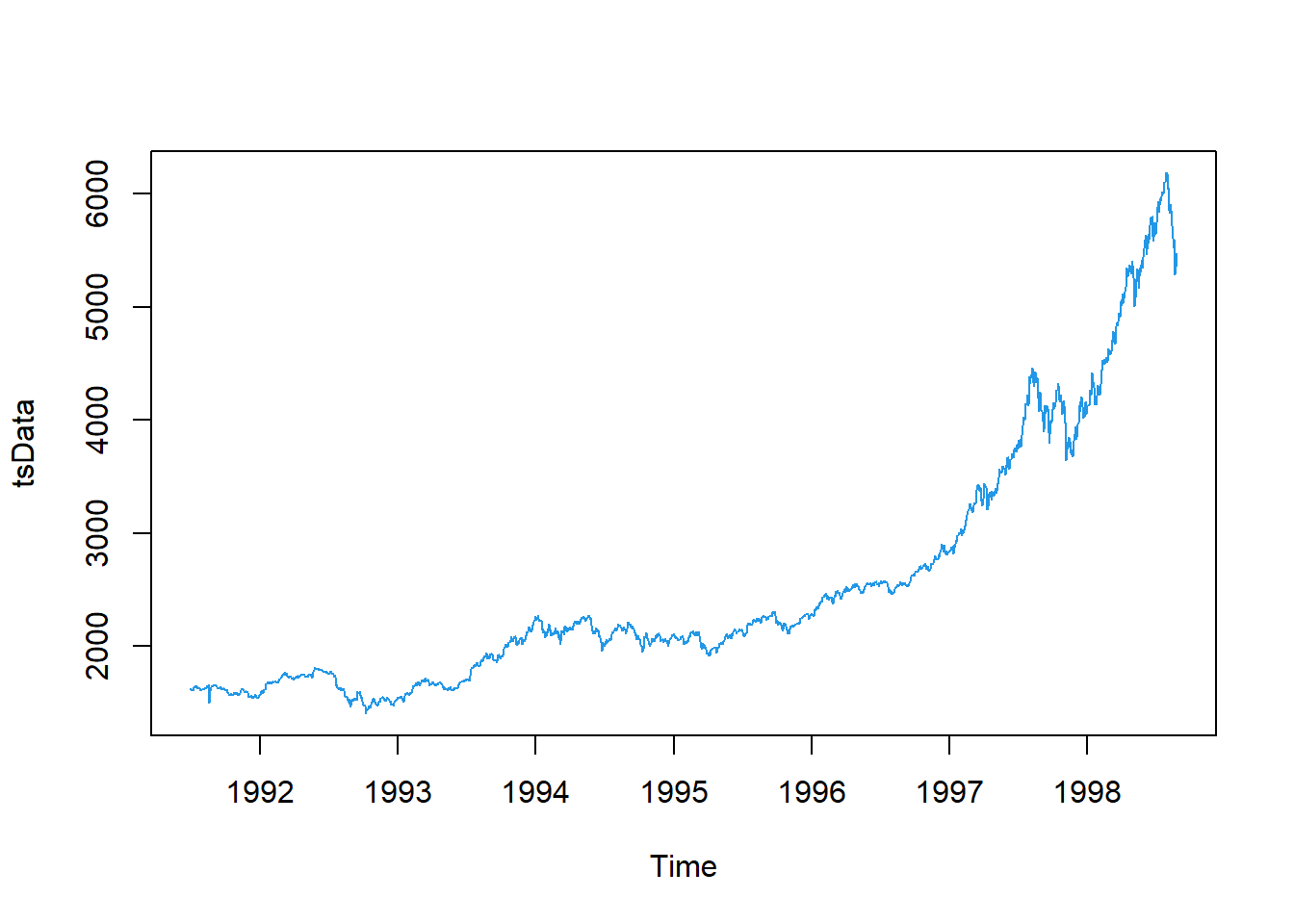
decomposedRes <- decompose(tsData, type="mult") # use type = "additive" for additive components
plot (decomposedRes,col=4) # see plot below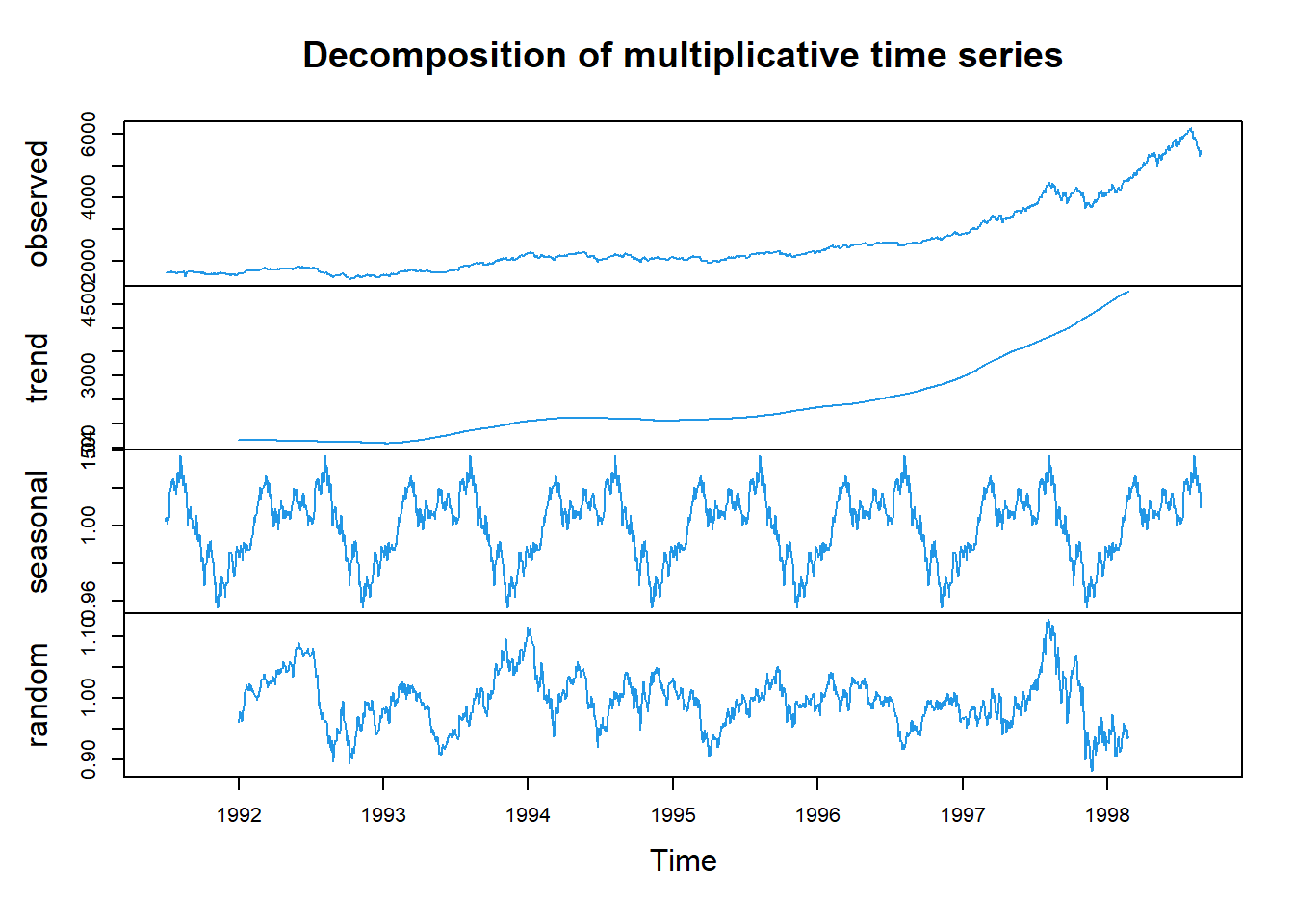
Gráfico de líneas
Muestran tendencias a lo largo de un período de tiempo, para diferentes niveles de una variable cualitativa, por lo tanto se usan para hacer comparaciones.
Ejemplo
Los siguientes datos describen el efecto de la vitamina c en el crecimiento de los dientes de un cerdo de guinea (Cuy), suministrado bajo dos formas diferentes, jugo de naranja y ácido ascorbico.
library(plotly)## Warning: package 'plotly' was built under R version 4.5.2##
## Adjuntando el paquete: 'plotly'## The following object is masked from 'package:ggplot2':
##
## last_plot## The following object is masked from 'package:stats':
##
## filter## The following object is masked from 'package:graphics':
##
## layoutdatn <- read.table(header=TRUE, text='
supp dose length
OJ 0.5 13.23
OJ 1.0 22.70
OJ 2.0 26.06
VC 0.5 7.98
VC 1.0 16.77
VC 2.0 26.14
')
datn2 <- datn
datn2$dose <- factor(datn2$dose)
p <- ggplot(data=datn2, aes(x=dose, y=length, group=supp, colour=supp)) +
geom_line() +
geom_point()
fig <- ggplotly(p)
figEjemplo en excel
Se tienen los precios de la zanahoria en las plazas de mercado de 3 ciudades diferentes
## fecha Bogota Arauca Armenia
## 1 4-ene 1700 1317 1556
## 2 11-ene 1472 1235 1389
## 3 18-ene 1288 1227 1400
## 4 25-ene 1321 1214 1365
## 5 1-feb 1492 1233 1211
## 6 8-feb 1392 1306 1211
## 7 15-feb 1544 1302 1211
## 8 22-feb 1389 1312 1294
## 9 29-feb 1296 1358 1294
## 10 7-mar 1229 1385 1206
## 11 14-mar 1867 1377 1122
## 12 21-mar 1973 1712 1639
## 13 28-mar 1158 1485 1324
## 14 4-abr 1313 1364 1194
## 15 11-abr 1398 1379 1144
## 16 18-abr 1658 1230 1128
## 17 25-abr 1708 1364 1406
## 18 2-may 2826 1811 1374
## 19 9-may 2081 2521 1524
## 20 16-may 2105 2264 1561
## 21 23-may 2208 2121 2037
## 22 30-may 2474 2230 2111
## 23 6-jun 2243 2424 1824
## 24 13-jun 1884 1794 1861
## 25 20-jun 1775 1800 1620
## 26 27-jun 2021 1448 1750Medidas de tendencia central
Son 3 valores que resumen y representan la información contenida en un conjunto de datos. Las tres medidas son la media, la mediana y la moda.

Moda
Es el valor que más se repite, si no hay datos que se repiten se dice que no hay moda. Si dos datos se repiten con la misma frecuencia se dice que los datos son bimodales.
Media
Valor promedio de un conjunto de datos numéricos, calculada como la suma del conjunto de valores dividida entre el número total de valores, la fórmula con la que se estima es:
| muestral | poblacional | |
|---|---|---|
| Media | \(\bar x=\frac{\sum_{i=1}^{n}x_i}{n}\) | \(\mu =\frac{\sum_{i=1}^{n}x_i}{N}\) |
| Tamaño | n | N |
Donde \(x_i\) corresponde a cada observación
Según el teorema de límite central cuando n>30 se considera poblacional
Mediana \(M_e\)
Es un valor que se encuentra en la mitad de los datos, cuando estos están ordenados
| Datos | Pares | Impares |
|---|---|---|
| Suma de los dos valores centrales dividida por dos | valor que se encuentra en la mitad | |
| Fórmula | \(\frac{X_{\frac{n}{2}}+X_{\frac{n}{2}+1}}{2}\) | \(X_\frac{_{n+1}}{2}\) |
Video medidas de tendencia central
Medidas de variabilidad
La media es un buen indicador de tendencia central, pero no da una evidencia real acerca de los datos.
Las medidas de variabilidad determinan el grado de acercamiento o distanciamiento de los valores de una distribución frente a su promedio de localización.
Entre más grande sea el grado de variación, menor uniformidad tendrán los datos (sinónimo de heterogeneidad) y por lo tanto menor confiabilidad del promedio de tendencia central o localización por haber sido obtenido de datos dispersos (Mendoza et al, 2002).
Si este valor es pequeño (respecto a la unidad de medida) entonces hay una gran uniformidad entre los datos(Mendoza et al, 2002).
Cuando es cero quiere decir que todos los datos son iguales.
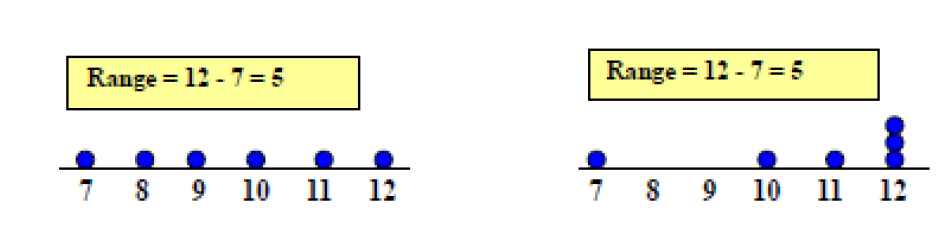
Rango
Es la diferencia entre el valor máximo y el valor mínimo
Rango= valor max - valor mínimo
Esta medida ignora la manera en que los datos están distribuidos
Varianza y Desviación estándar
Indica qué tan dispersos están los datos con respecto a la media
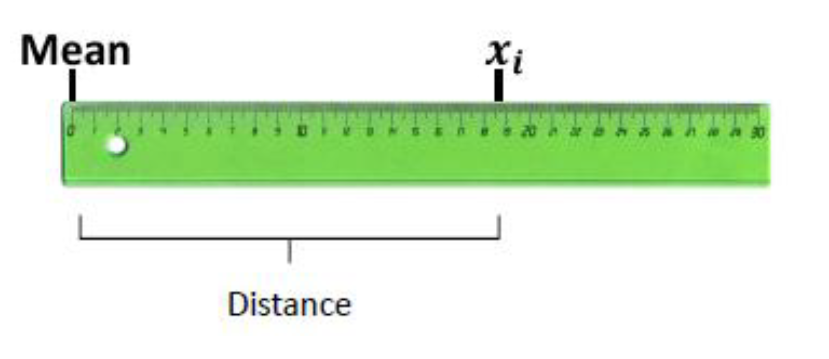
| Parametro poblacional | Estadístico muestral | |
|---|---|---|
| Varianza | \(\sigma^2=\frac{\sum_{i=1}^n(x_i-\mu)^2}{N}\) | \(S^2=\frac{\sum_{i=1}^n(x_i-\bar x)^2}{n-1}\) |
| Desviación estándar | \(\sigma=\sqrt{\frac{\sum_{i=1}^n(x_i-\mu)^2}{N}}\) | \(S=\sqrt{\frac{\sum_{i=1}^n(x_i-\bar x)^2}{n-1}}\) |
Medidas de variabilidad
Diferencia en medidas entre la población y la muestra
| Medida | Población | Muestra |
|---|---|---|
| Tamaño | N | n |
| Media | \(\mu\) | \(\bar x\) |
| Varianza | \(\sigma^2\) | \(S^2\) |
| Desviación estándar | \(\sigma\) | S |
Comparemos
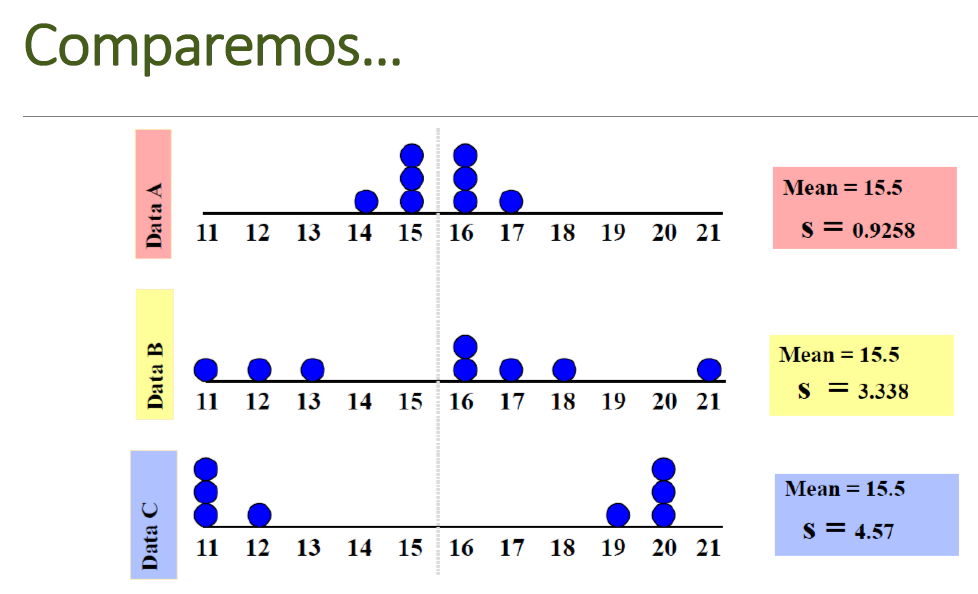
Cómo estimar la media, la desviación estandar en la calculadora
Coeficiente de variación
Es una medida de la dispersión relativa de un conjunto de datos, la cual relaciona la desviación típica de una muestra y su media.
Se expresa en términos porcentuales, la fórmula con la que se estima es: \[CV=\frac{S}{\bar x}*100\]
No depende de las unidades de medición, por lo que sirve para comparar la variabilidad de dos conjuntos de datos, siempre que sus medias sean positivas.
Ejemplo
Se tienen las edades de una muestra de estudiantes de estadística básica compuesta por hombres y mujeres
| Hombre | 20 | 22 | 26 | 20 | 26 | 19 | 20 | 21 | 26 | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mujer | 20 | 20 | 31 | 26 | 23 | 42 | 23 | 20 | 24 | 25 | 24 | 27 | 22 |
Estime las medidas de variación y el coeficiente de variación.
Media ponderada
Es apropiada cuando en un conjunto de datos, cada uno de ellos tiene una importancia relativa (o peso) respecto de los demás datos. Se obtiene multiplicando cada uno de los datos por su ponderación (peso) para luego sumarlos
\[\bar X=\sum_{i=1}^{n}x_i*w_i\]
Donde \(X_i\) es cada una de las observaciones, \(W_i\) es la ponderación de cada uno de ellos.
\[\sum_{i=1}^n w_i=1\]
Ejemplo
Se tienen las siguientes notas de un estudiante
| Peso(%) | 25 | 15 | 35 | 10 | 15 | total |
|---|---|---|---|---|---|---|
| Nota | 4 | 3 | 2 | 1 | 4 | |
| Ponderación | 1 |
¿Cuál es la nota total obtenida en la materia?
Si faltara la última nota,¿Cuanto tendría que sacar para ganar la asignatura?
Medidas de posición
Son valores que permiten dividir el conjunto de datos en partes porcentuales iguales y se usan para clasificar una observación dentro de una población o muestra. Las medidas de posición más usuales son los cuartiles, los deciles y los percentiles.
Cuartiles
Son tres valores que distribuyen la serie de datos ordenada, en cuatro tramos iguales, en los que cada uno de ellos se concentra el 25% de los resultados.
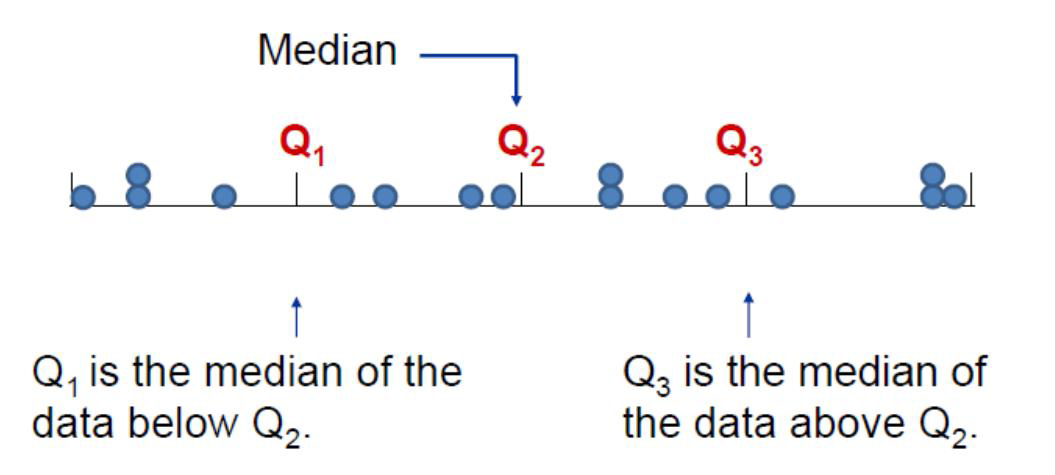
La fórmula con la que se estima está dada por:
\[Q_k=X_{(k \frac{n+1}{4})}\] con k=1,2,3
Rango intercuartilico IQR Se define como la diferencia entre el tercer cuartil y el primer cuartil, es decir:
\[IRQ=Q_3-Q_1\]
The Interquartile Range (or IQR)
Deciles
Son 9 valores que distribuyen la serie de datos ordenada, en diez tramos iguales, en los que cada uno de ellos concentra el 10% de los resultados.
La fórmula con la que se estima está dada por:
\[D_k=X_{(k \frac{n+1}{10})}\] con k=1,2,3…9
Percentiles
Divide un conjunto de datos ordenados en 100 partes iguales, es decir hay 99 percentiles.
\[P_k=X_{(k \frac{n+1}{100})}\] con k=1,2,3…99
Boxplot
El boxplot es una herramienta de análisis que resalta las principales características de un conjunto de datos, los números usados para construirlo son:
- Valor mínimo
- Los cuartiles \(Q_1,Q_2,Q_3\)
- Valor máximo
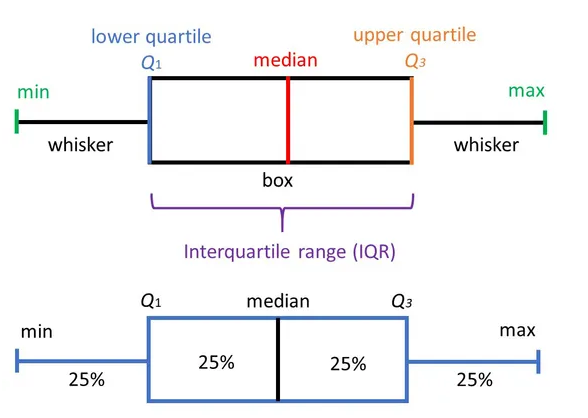
Cada sección contiene el 25% de los datos. La caja muestra la mitad de los datos, es decir el 50% de ellos, contiene la información entre el 3 cuartil y el primer cuartil.
Sirve para realizar comparaciones de una variable cuantitativa, en relación a los niveles de una variable cualitativa.
Es posible observar la dispersión de cada caja, mientras mas larga, más dispersión.
Permite observar puntos atípicos,los cuales no están contenidos dentro de la caja, ni en sus bigotes.
Ejemplo en R
La siguiente información fue reportada en la revista Motor Trend de EE.UU, en el año 1974. contiene el consumo de combustible y 10 aspectos del diseño y rendimiento para 32 automóviles (modelos 1973–74).
A continuación se ilustra un resumen del número de cilindros que cada uno de los automoviles mostró
library(knitr)
library(ggplot2)
#Base de datos
head(mtcars)## mpg cyl disp hp drat wt qsec vs am gear carb
## Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
## Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
## Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
## Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
## Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
## Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1#resumen de todas las variables de la base de datos
summary(mtcars)## mpg cyl disp hp
## Min. :10.40 Min. :4.000 Min. : 71.1 Min. : 52.0
## 1st Qu.:15.43 1st Qu.:4.000 1st Qu.:120.8 1st Qu.: 96.5
## Median :19.20 Median :6.000 Median :196.3 Median :123.0
## Mean :20.09 Mean :6.188 Mean :230.7 Mean :146.7
## 3rd Qu.:22.80 3rd Qu.:8.000 3rd Qu.:326.0 3rd Qu.:180.0
## Max. :33.90 Max. :8.000 Max. :472.0 Max. :335.0
## drat wt qsec vs
## Min. :2.760 Min. :1.513 Min. :14.50 Min. :0.0000
## 1st Qu.:3.080 1st Qu.:2.581 1st Qu.:16.89 1st Qu.:0.0000
## Median :3.695 Median :3.325 Median :17.71 Median :0.0000
## Mean :3.597 Mean :3.217 Mean :17.85 Mean :0.4375
## 3rd Qu.:3.920 3rd Qu.:3.610 3rd Qu.:18.90 3rd Qu.:1.0000
## Max. :4.930 Max. :5.424 Max. :22.90 Max. :1.0000
## am gear carb
## Min. :0.0000 Min. :3.000 Min. :1.000
## 1st Qu.:0.0000 1st Qu.:3.000 1st Qu.:2.000
## Median :0.0000 Median :4.000 Median :2.000
## Mean :0.4062 Mean :3.688 Mean :2.812
## 3rd Qu.:1.0000 3rd Qu.:4.000 3rd Qu.:4.000
## Max. :1.0000 Max. :5.000 Max. :8.000#millas por galón
mpg=mtcars[,1]
#media de las millas por galón
mean(mpg)## [1] 20.09062#desviación estándar
sd(mpg)## [1] 6.026948##Media de mpg según elnúmero de cilindros
# Usually, you'll want to group first
mtcars %>%
group_by(cyl) %>%
summarise(mean = mean(mpg))## # A tibble: 3 × 2
## cyl mean
## <dbl> <dbl>
## 1 4 26.7
## 2 6 19.7
## 3 8 15.1#boxplot
boxplot(mtcars[,1]~mtcars[,2],xlab="cilindros",ylab="mpg",col ="pink")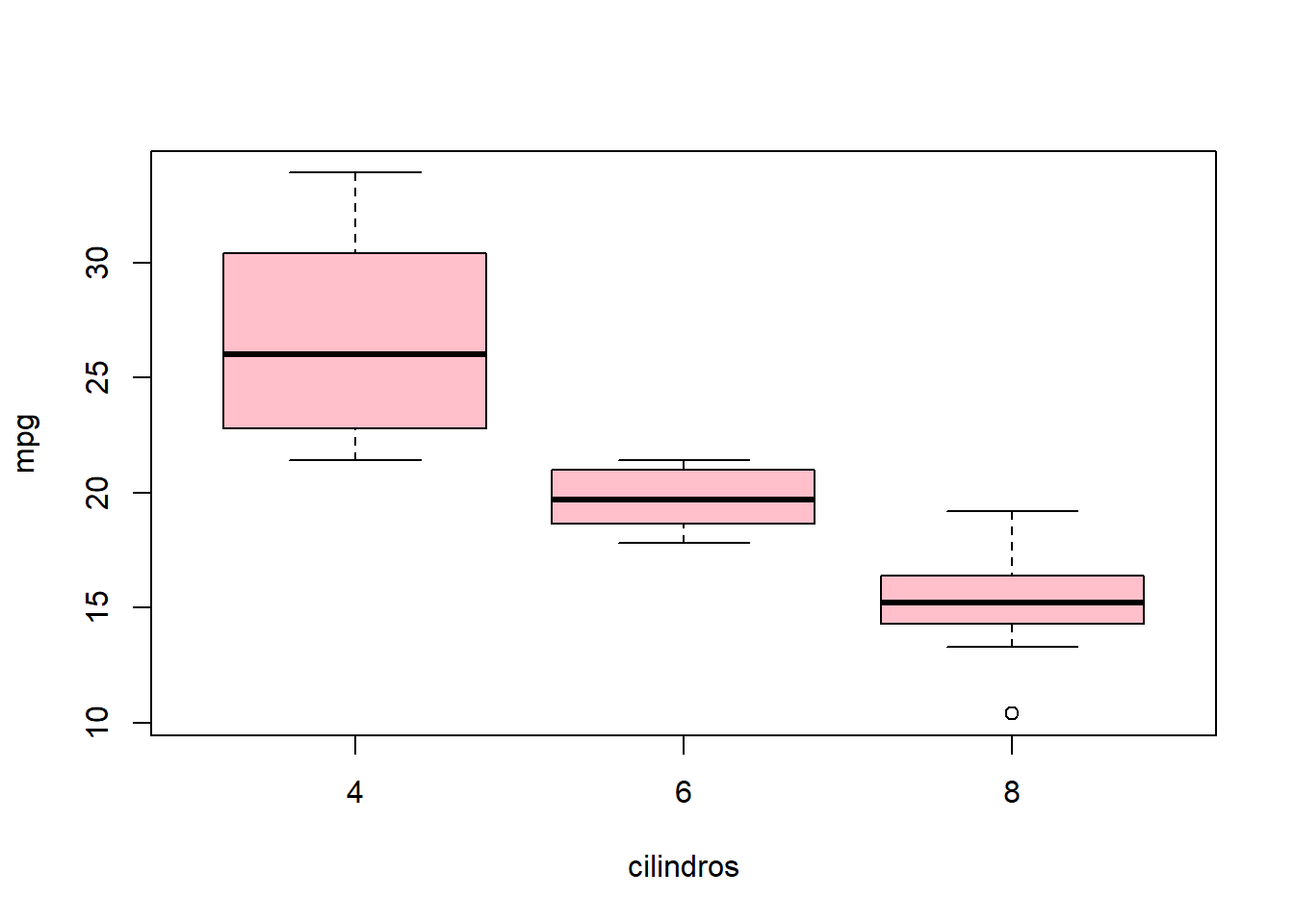
Medidas de forma
Permiten identificar si una distribución de frecuencia presenta uniformidad. Son necesarias para determinar el comportamiento de los datos. Se clasifican en Medidas de asimetría y medidas de curtosis
Medidas de asimetría
Permite establecer el grado de simetría que tiene una distribución
Coeficiente de asimetría de Pearson
Relaciona la media y la moda de un conjunto de datos
\[A_s=\frac{\bar x-M_o}{S}\]
Distribución Simétrica
\[\bar X=M_o=M_e\] - Cuando \(\bar X<M_e\) decimos que la distribución es Asimétrica a la izquierda, Asimétrica de cola izquierda o que tiene Asimetría negativa
- Cuando \(\bar X>M_e\) decimos que la distribución es Asimétrica a la derecha, Asimétrica de cola derecha o que tiene Asimetría positiva
Comparemos
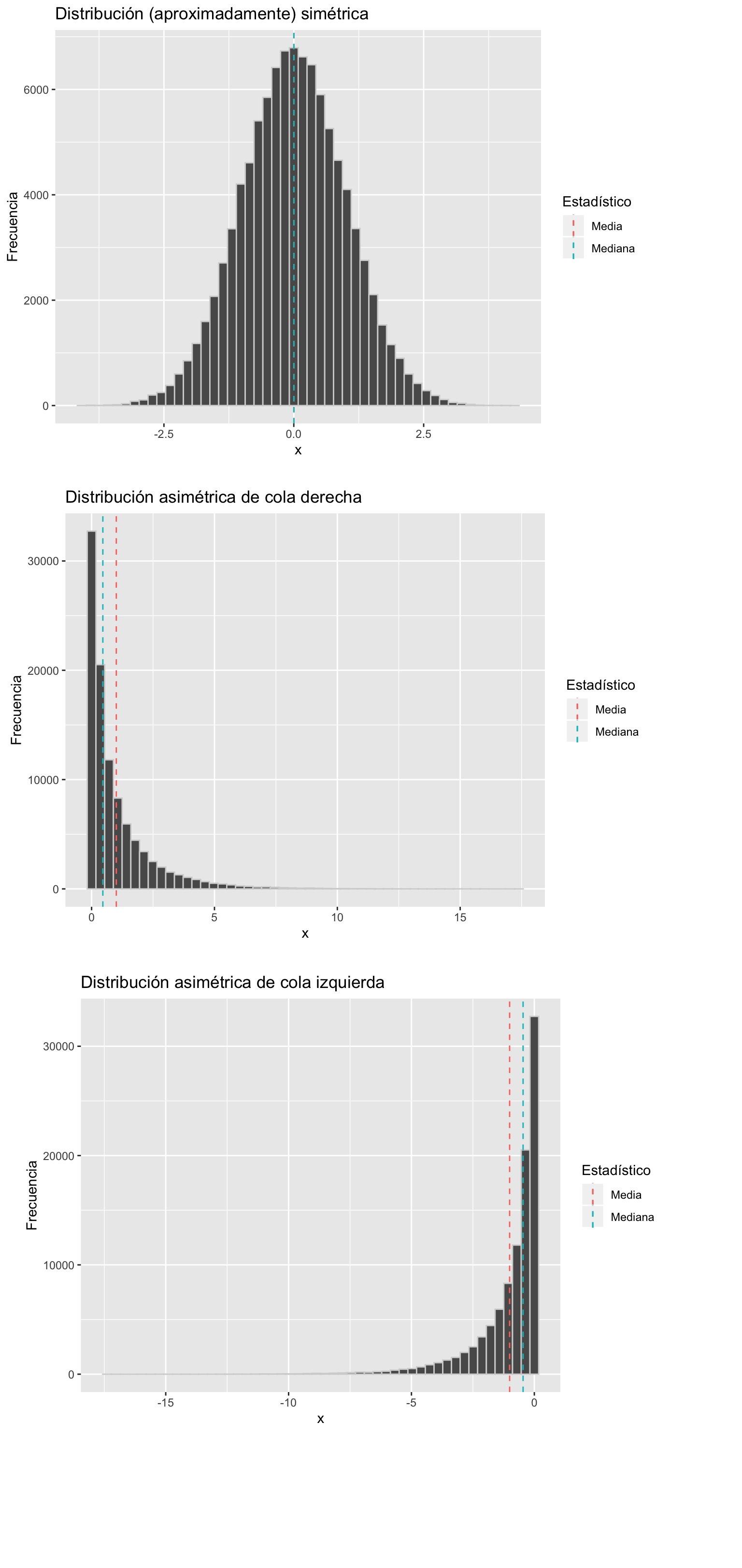
Medidas de curtosis
Medida que sirve para analizar el grado de concentración que presentan los valores de una variable analizada alrededor de la zona central de la distribución de frecuencias, la kurtósis se conoce como una medida del apuntalamiento de la distribución. Se definen tres tipos de distribuciones según su grado de curtosis, mesocurtica, platicurtica, leptocurtica.
Comparemos

Gráfico de densidad
Visualiza la distribución de datos en un intervalo o período de tiempo continuo. Este gráfico es una variación de un histograma, donde el concepto de frecuencia relativa se cambia por el de probabilidad, la suma de todas la superficie será 1.
Los picos ayudan a mostrar dónde los valores se concentran en el intervalo, a su vez permite comparar la densidad de una variable continua en relación a los niveles de factor de una variable cualitativa.
Ejemplo
Comparar la densidad de las alturas de hombres y mujeres.
library(ggplot2)
# datos
head(si)## [1] 9.4 9.0 6.8 7.2 7.7 8.3head(no)## [1] 3.7 8.1 8.3 9.1 5.6 10.2par(mfrow=c(1,2))
tmp <- rbind(data.frame(origen = "no", dato = no),
data.frame(origen = "si", dato = si))
ggplot(tmp, aes(x =dato, fill = origen)) +
geom_density(alpha = 0.3)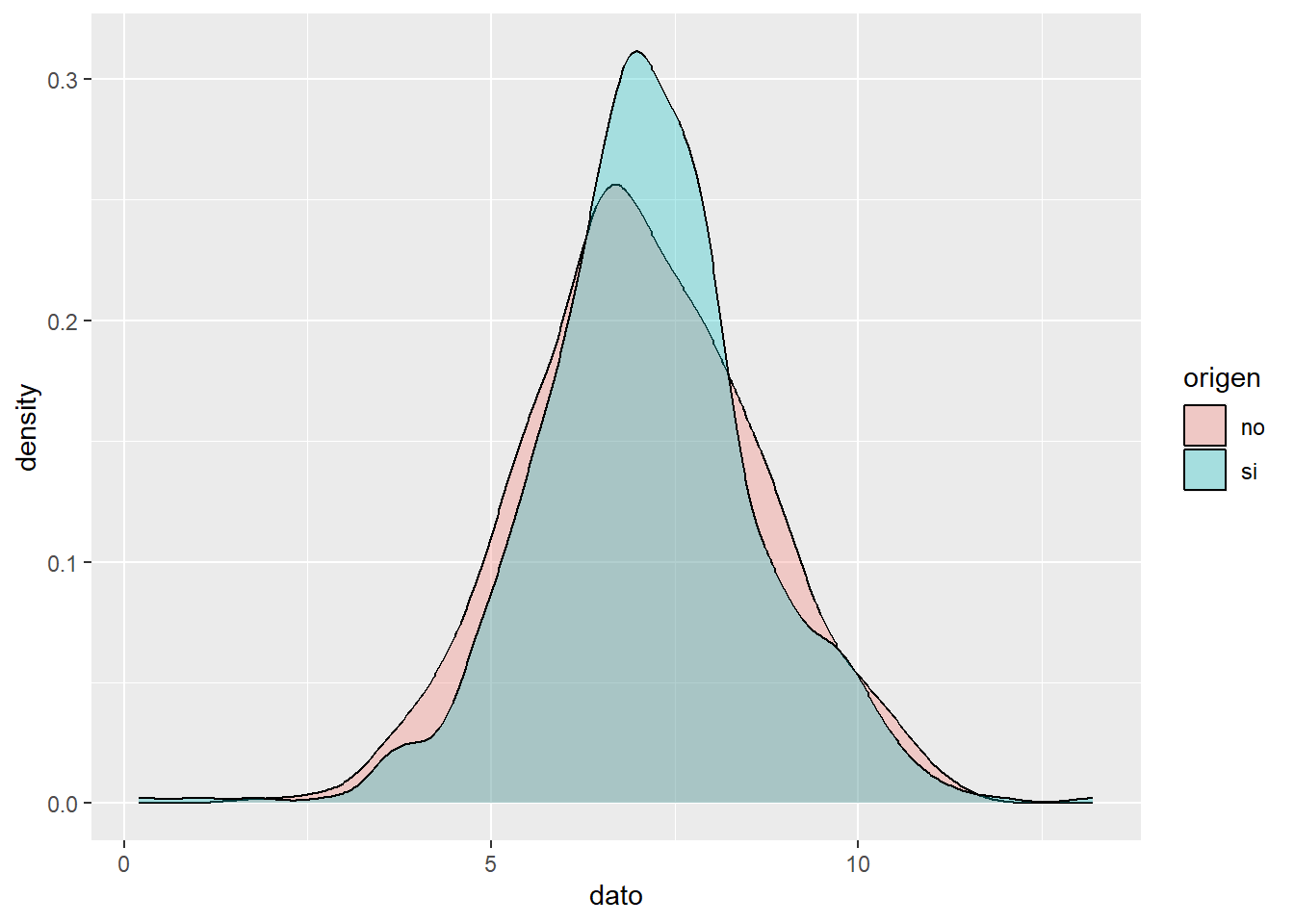
hist(no, xlab = "PH agua no potable", ylab = "Frecuencia", las=1, main = "", col = "gray")
hist(si, xlab = "PH agua potable", ylab = "Frecuencia", las=1, main = "", col = "gray")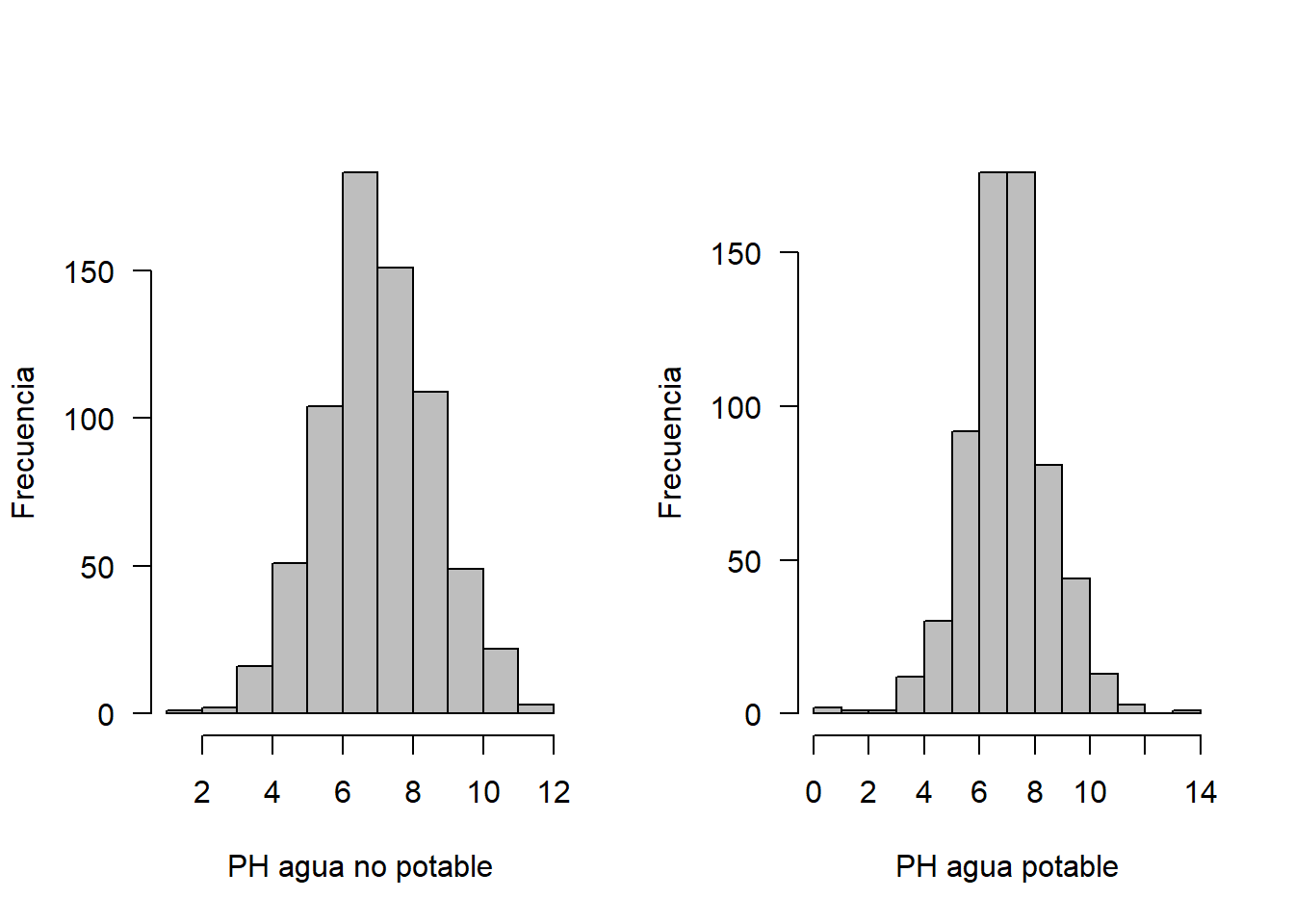
Medidas de tendencia central en tablas de frecuencia
Tabla de datos agrupados
Cuando los valores de la variable (continuas o discretas) son muchos, conviene agrupar los datos en intervalos o clases para así realizar un mejor análisis e interpretación de ellos.
Proceso para la construcción de la tabla de frecuencia para datos agrupados
- Se elige ó se calcula el número de intervalos de clase representado por la variable m se puede usar la fórmula
\[m=\sqrt n\] 2. Calcule el rango R
- Calcule la amplitud de los intervalos, el cual se denota por la letra a:
\[a=\frac{R}{m}\] 4. Calcule los intervalos de clase: son dos columnas que delimitan el límite superior e inferior del intervalo (LI y LS)
El intervalo es cerrado a la izquierda y abierto a la derecha \([x_1,x_2)\)
El último intervalo es cerrado a ambos lados, para no dejar información fuera del rango
- Se busca la marca de clase que se denota por 𝑋𝑖 dada por
\[X_i=\frac{L_{infi}+L_{supi}}{2}\]
- Otra columna de la tabla para datos agrupados es la frecuencia absoluta(𝑓𝑖):
Es el número de observaciones que caen en un intervalo sin incluir el limite superior, es decir número de datos mayores o iguales al límite inferior pero menores que el límite superior
Es decir el intervalo es cerrado a la izquierda y abierto a la derecha. El último intervalo es cerrado a ambos lados, para no dejar información fuera del rango
- Se busca las otras columnas que corresponden a la Frecuencia absoluta acumulada \(F_i\), frecuencia relativa \(h_i\) y frecuencia relativa acumulada \(H_i\)
| intervalo | Límite inferior | Límite superior | \(x_i\) | \(f_i\) | \(F_i\) | \(h_i\) | \(H_i\) |
|---|---|---|---|---|---|---|---|
| 1 | \([X_{min}\) | \(L_{s1}=L_{inf1}+a)\) | \(x_1\) | \(f_1\) | \(F_1=f_1\) | \(h_1\) | \(H_1=h_1\) |
| 2 | [\(L_{inf2}=L_{sup1}\) | \(L_{sup2}=L_{inf2}+a)\) | \(x_2\) | \(f_2\) | \(F_2=f_1+f_2\) | \(h_2\) | \(H_2=h_1+h_2\) |
| \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\vdots\) | |
| m | [\(L_{infm}\) | max] | \(x_m\) | \(f_m\) | n |
Media de datos agrupados
\[\bar x=\frac{\sum_{i=1}^n X_if_i}{n}\] Donde: \(X_i\) es la marca de clase
\(f_i\) es la frecuencia relativa
n tamaño de la muestra
También es posible encontrar el intervalo modal y el intervalo de la mediana
Tablas de frecuencia para variables cuantitativas Se tiene la edad de 96 estudiantes nuevos del itm
| v1 | v2 | v3 | v4 | v5 | v6 | v7 | v8 | v9 | v10 | v11 | v12 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 18 | 26 | 19 | 19 | 21 | 33 | 18 | 18 | 18 | 37 | 18 | 33 |
| 21 | 34 | 19 | 18 | 18 | 21 | 27 | 20 | 21 | 18 | 29 | 17 |
| 28 | 26 | 25 | 28 | 29 | 23 | 27 | 18 | 17 | 42 | 20 | 18 |
| 24 | 18 | 24 | 19 | 26 | 25 | 24 | 19 | 22 | 21 | 26 | 18 |
| 19 | 21 | 25 | 21 | 26 | 17 | 17 | 21 | 20 | 27 | 16 | 18 |
| 21 | 23 | 41 | 23 | 43 | 26 | 49 | 19 | 21 | 18 | 34 | 23 |
| 17 | 17 | 23 | 18 | 26 | 24 | 23 | 21 | 30 | 18 | 18 | 20 |
| 21 | 31 | 20 | 33 | 21 | 20 | 18 | 17 | 27 | 23 | 27 | 28 |
Ejemplo en R
El siguiente conjunto de datos da las medidas en centimetros de las variables largo y ancho, tanto del sepalo como del petalo, para 3 especies de flores, iris setosa, versicolor y virginica.
#install.packages("janitor")
library(dplyr)##
## Adjuntando el paquete: 'dplyr'## The following objects are masked from 'package:stats':
##
## filter, lag## The following objects are masked from 'package:base':
##
## intersect, setdiff, setequal, unionhead(iris)## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3.0 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5.0 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa#SE ESCOGE LA VARIABLE LARGO DE SEPALO
iris %>%
group_by(iris$Sepal.Length) %>%
summarise(frequency = n())## # A tibble: 35 × 2
## `iris$Sepal.Length` frequency
## <dbl> <int>
## 1 4.3 1
## 2 4.4 3
## 3 4.5 1
## 4 4.6 4
## 5 4.7 2
## 6 4.8 5
## 7 4.9 6
## 8 5 10
## 9 5.1 9
## 10 5.2 4
## # ℹ 25 more rowsLa salida de R no muestra todas las entradas, porque son 35 valores diferentes, conviene agruparlos, por intervalos de frecuencias.
iris %>%
mutate(sepal_length_group = cut(iris$Sepal.Length, breaks = 5)) %>%
group_by(sepal_length_group) %>%
summarise(frequency = n())## # A tibble: 5 × 2
## sepal_length_group frequency
## <fct> <int>
## 1 (4.3,5.02] 32
## 2 (5.02,5.74] 41
## 3 (5.74,6.46] 42
## 4 (6.46,7.18] 24
## 5 (7.18,7.9] 11Podemos agregar una columna más a la tabla de frecuencias, acumulando las frecuencias para cada clase, utilizando la función cumsum.
breaks <- seq(from = 4, to = 8, by = 1)
iris %>%
mutate(
sepal_length_group = cut(iris$Sepal.Length, breaks = breaks)
) %>%
group_by(sepal_length_group) %>%
summarise(frequency = n()) %>%
mutate(cum_frequency = cumsum(frequency))## # A tibble: 4 × 3
## sepal_length_group frequency cum_frequency
## <fct> <int> <int>
## 1 (4,5] 32 32
## 2 (5,6] 57 89
## 3 (6,7] 49 138
## 4 (7,8] 12 150#"install.packages(ggplot2)
library(ggplot2)
breaks <- seq(from = 4, to = 8, by = 1)
iris %>%
mutate(sepal_length_group = cut(iris$Sepal.Length, breaks = breaks)) %>%
group_by(sepal_length_group) %>%
summarise(frequency = n()) %>%
ggplot() +
geom_bar(aes(x = sepal_length_group, y = frequency), stat = 'identity',col=3)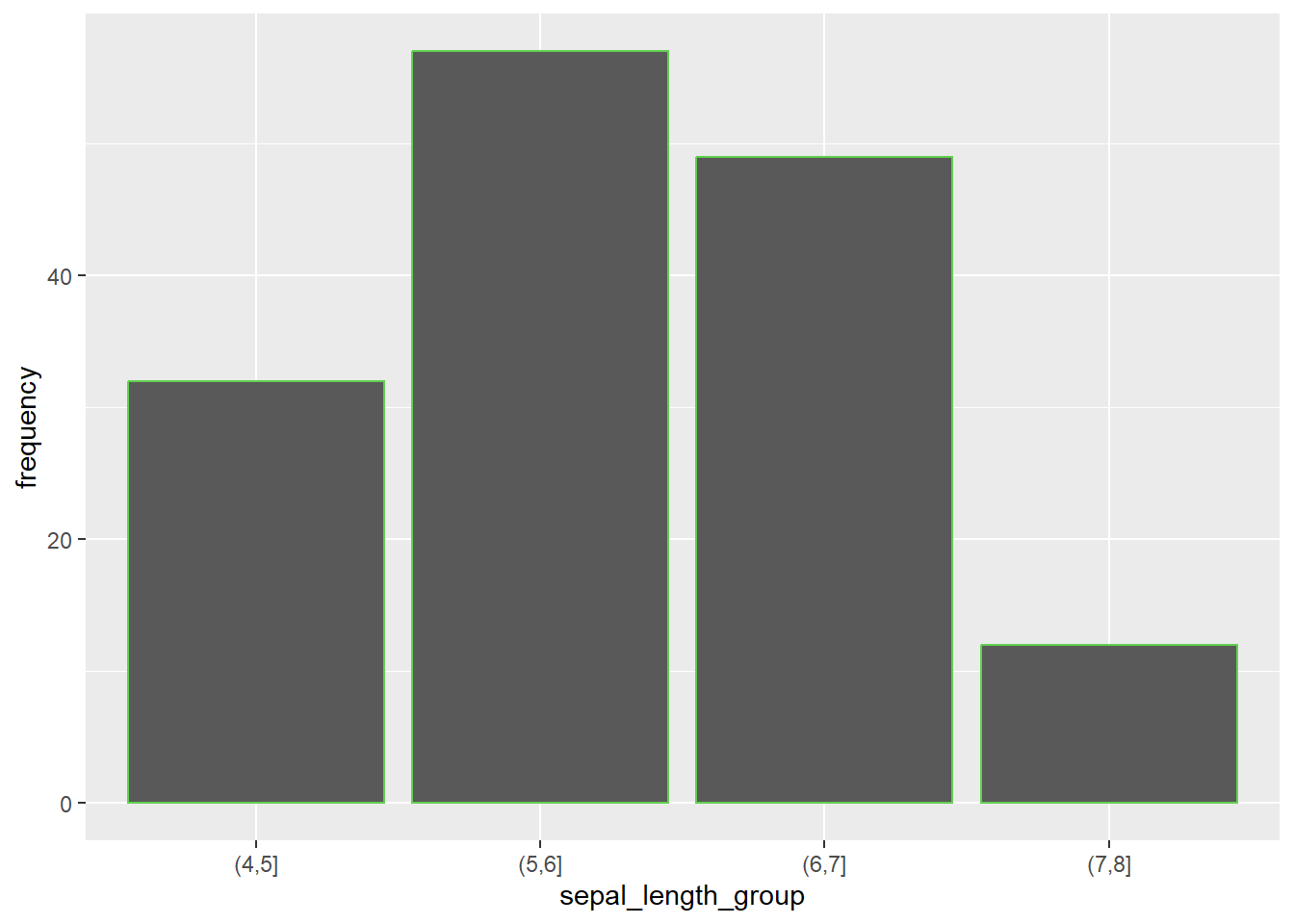
Analisis de datos agrupados
medidas de tendencia central en datos agrupados
Bibliografía
Mendoza, H, Bautista, G. (2002). Probabilidad y Estadística. Universidad Nacional de Colombia, http://www.virtual.unal.edu.co/cursos/ciencias/2001065/. Licencia: Creative Commons BY-NC-ND.
R Core Team (2019). R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. URL https://www.R-project.org/.