Graficos diagnósticos de la distribución de los datos
Graficos para analizar la distribución de los datos
Gran parte de los modelos estadísticos consideran que las observaciones provienen de poblaciones normales. En muchas situaciones este supuesto no se cumple. A continuación se mencionan algunos gráficos utilizados para analizar la distribución de los datos, además de la detección de puntos atípicos.
En metrología los datos atípicos son llamados valores aberrantes, conocidos como las observaciones que se desvían significativamente de la tendencia general de los datos o que están considerablemente alejados de otros valores de la muestra. La detección y gestión de valores aberrantes es importante en metrología para garantizar la precisión y fiabilidad de las mediciones. Los valores aberrantes pueden sesgar los resultados del análisis y afectar la toma de decisiones basada en los datos.
Gráfico de densidad
Visualiza la distribución de datos en un intervalo continuo. Este gráfico es una variación de un histograma, donde el concepto de frecuencia relativa se cambia por el de probabilidad, la suma de todas la superficie será 1.
Los picos ayudan a mostrar dónde los valores se concentran en el intervalo, a su vez permite comparar la densidad de una variable continua en relación a los niveles de factor de una variable cualitativa.
Ejemplo
El acceso al agua potable es esencial para la salud, un derecho humano básico y un componente de una política eficaz de protección de la salud. Esto es importante como cuestión de salud y desarrollo a nivel nacional, regional y local. En algunas regiones, se ha demostrado que las inversiones en abastecimiento de agua y saneamiento pueden generar un beneficio económico neto, ya que las reducciones de los efectos adversos para la salud y los costos de atención médica superan los costos de llevar a cabo las intervenciones.
El PH es un parámetro importante para evaluar el equilibrio ácido-base del agua. La OMS ha recomendado un límite máximo permitido de pH de 6,5 a 8,5.
Se tienen los datos del ph del agua dependiendo de si el agua es potable o no, 632 datos de agua potable y 632 de agua no potable, se desea comparar su distribución.
library(ggplot2)
head(no)## [1] 3.7 8.1 8.3 9.1 5.6 10.2head(si)## [1] 9.4 9.0 6.8 7.2 7.7 8.3# datos
par(mfrow=c(1,2))
tmp <- rbind(data.frame(origen = "no", dato = no),
data.frame(origen = "si", dato = si))
ggplot(tmp, aes(x =dato, fill = origen)) +
geom_density(alpha = 0.3)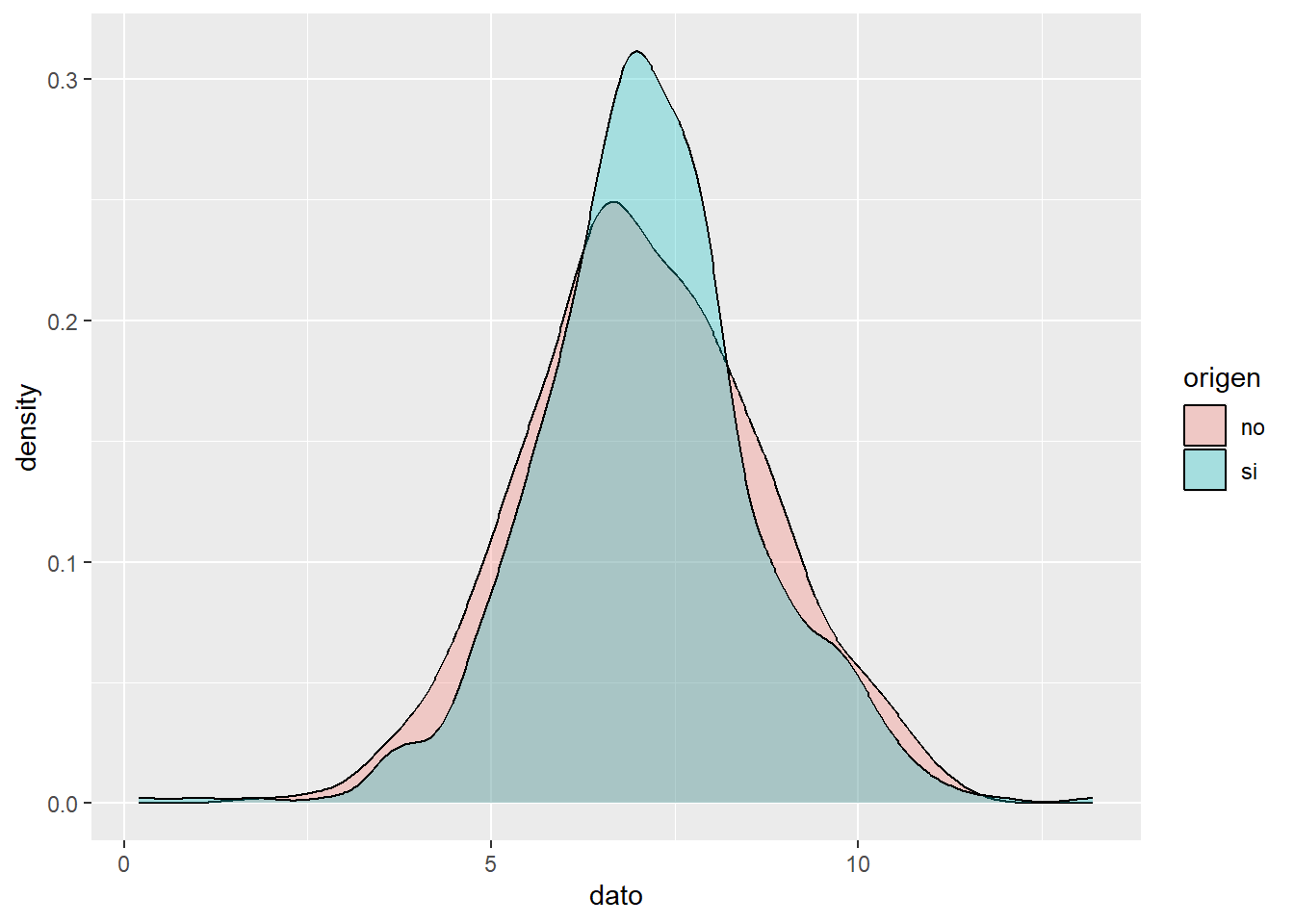
hist(no, xlab = "PH agua no potable", ylab = "Frecuencia", las=1, main = "", col = "gray")
hist(si, xlab = "PH agua potable", ylab = "Frecuencia", las=1, main = "", col = "gray")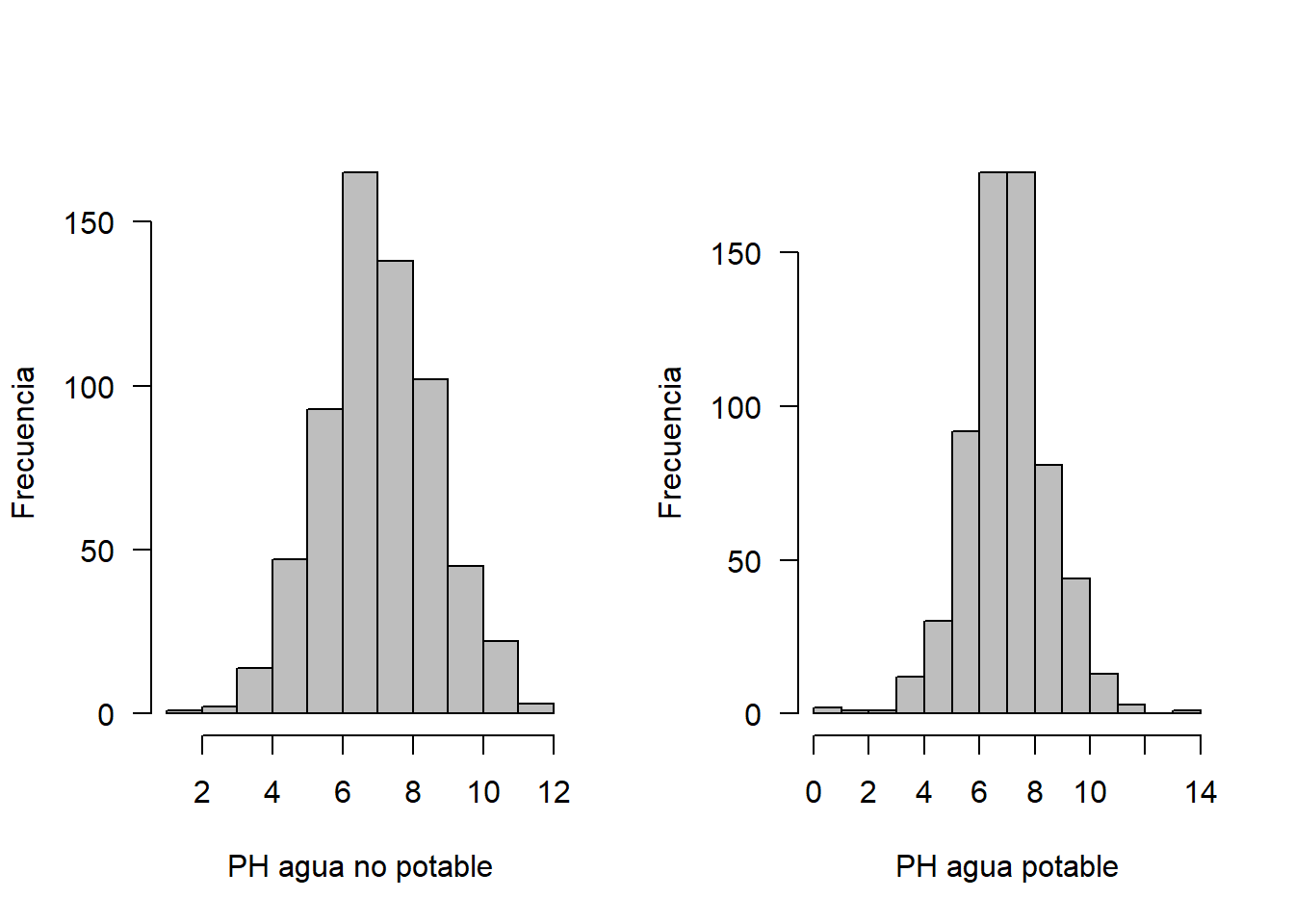
Grafico cuantil cuantil
Los gráficos cuantil cuantil son una ayuda para explorar si un conjunto de datos proviene de una población con cierta distribución.
La función qqnorm sirve para explorar la normalidad de una muestra, generalmente va acompañada de una linea recta de referencia, que se estima con la función qqline.
La función qqplot sirve para crear el gráfico cuantil cuantil para cualquier distribución, requiere los cuantiles de la distribución candidata.
Ejemplo de los datos de agua potable
par(mfrow=c(1, 2))
qqnorm(y=si, main='PH agua potable', ylab='Cuantiles muestrales',
xlab='Cuantiles teóricos', las=1)
qqline(y=si, col='blue', lwd=2, lty=2)
qqnorm(y=no, main='PH agua no potable', ylab='Cuantiles muestrales',
xlab='Cuantiles teóricos', las=1)
qqline(y=no, col='blue', lwd=2, lty=2)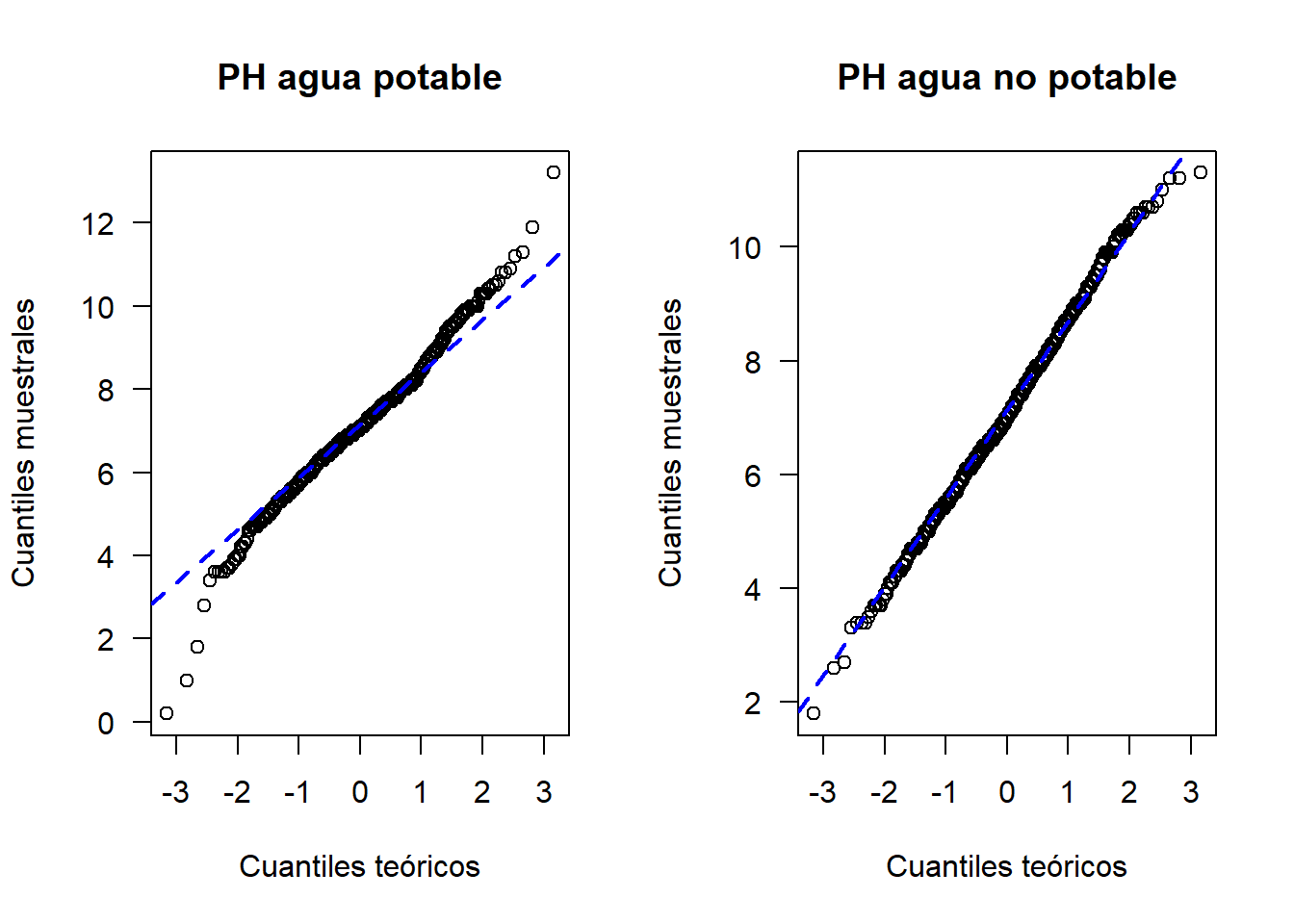
Boxplot
El boxplot es una herramienta de análisis que resalta las principales características de un conjunto de datos, los números usados para construirlo son:
- Valor mínimo
- Los cuartiles \(Q_1,Q_2,Q_3\)
- Valor máximo
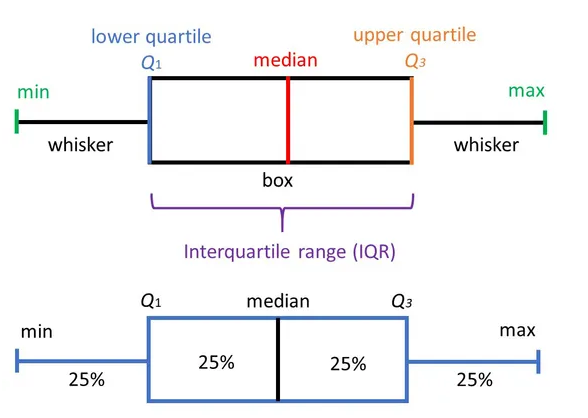
Cada sección contiene el 25% de los datos. La caja muestra la mitad de los datos, es decir el 50% de ellos, contiene la información entre el 3 cuartil y el primer cuartil.
Sirve para realizar comparaciones de una variable cuantitativa, en relación a los niveles de una variable cualitativa.
Es posible observar la dispersión de cada caja, mientras mas larga, más dispersión.
Permite observar puntos atípicos,los cuales no están contenidos dentro de la caja, ni en sus bigotes.
Ejemplo
construir un boxplot con los datos del ph del agua según su potabilidad, Qué infiere?
boxplot(no,si)
abline(h=6.5,col=2)
abline(h=8.5,col=2)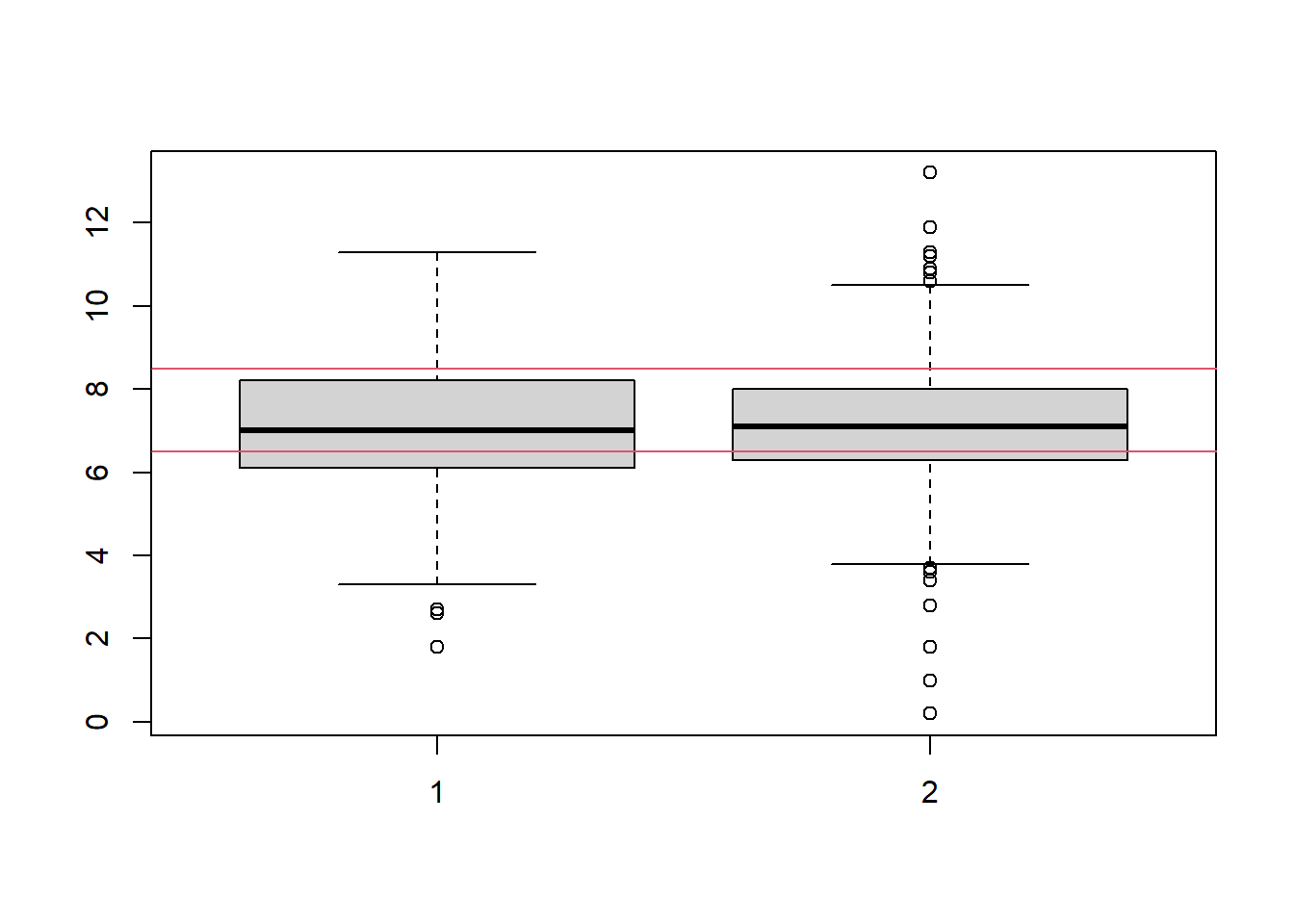
Pruebas de bondad de ajuste para distribuciones de probabilidad
Pruebas de normalidad
La hipotesis nula y alternativa de normalidad son las siguientes:
\[H_0: \quad Los\quad datos\quad se\quad distribuyen \quad normal\]
\[H_1: \quad Los\quad datos\quad no \quad se\quad distribuyen \quad normal\] Existen diferentes pruebas para evaluar la normalidad, todas son de fácil implementación en R.
- Prueba Shapiro-Wilk
En R se usa la función shapiro.test, se usa cuando la muestra es como máximo de tamaño 50. Es más potente que la prueba de K-S.
Prueba Anderson-Darling con la función ad.test del paquete nortest.
Prueba Cramer-von Mises con la función cvm.test del paquete nortest.
Prueba Lilliefors (Kolmogorov-Smirnov) con la función lillie.test del paquete nortest.
Prueba Pearson chi-square con la función pearson.test del paquete nortest.
Prueba Shapiro-Francia con la función sf.test del paquete nortest.
Ejemplo en R probando normalidad en los datos de potabilidad del agua
Para los datos del ph del agua, se desea probar mediante una prueba estadística si los datos se distribuyen de forma normal
shapiro.test(no)##
## Shapiro-Wilk normality test
##
## data: no
## W = 0.99749, p-value = 0.4571shapiro.test(si)##
## Shapiro-Wilk normality test
##
## data: si
## W = 0.9852, p-value = 5.12e-06Otro Ejemplo en R
Se necesita verificar si es correcto suponer que el volumen de llenado (en onzas) de una máquina dispensadora de jugos sigue una distribución normal, por lo que se toman 25 botellas de forma aleatoria. Los datos del volumen de llenado obtenidos de la muestra se encuentran almacenados en el vector volumen.
Hipótesis
\(H_0:\) el volumen de llenado (en onzas) sigue una distribución normal.
\(H_1:\) el volumen de llenado (en onzas) no sigue una distribución normal.
Nivel de significancia: 0.05 (Hipotético).
Analisis descriptivo
library(nortest)## Warning: package 'nortest' was built under R version 4.5.2volumen <-c(8.39,12.14,11.80,12.04,7.34,12.62,11.51,12.47,11.08,14.32,11.33,11.56, 12.79,11.72,12.84,11.73,12.1,11.88,11.95,10.84,11.79,13.21,12.56,12.55,12.80)
mean(volumen)## [1] 11.8144sd(volumen)## [1] 1.4036require(car)## Cargando paquete requerido: car## Cargando paquete requerido: carDatalibrary(MASS)
par(mfrow=c(1,4))
hist(volumen, xlab = "Volumen de llenado", ylab = "Frecuencia", las=1, main = "", col = "gray")
plot(density(volumen), xlab = "Volumen de llenado", ylab = "Densidad", las=1, main = "")
qqPlot(volumen, xlab="Cuantiles teóricos", ylab="Cuantiles muestrales", las=1,main="")## [1] 5 1boxplot(volumen)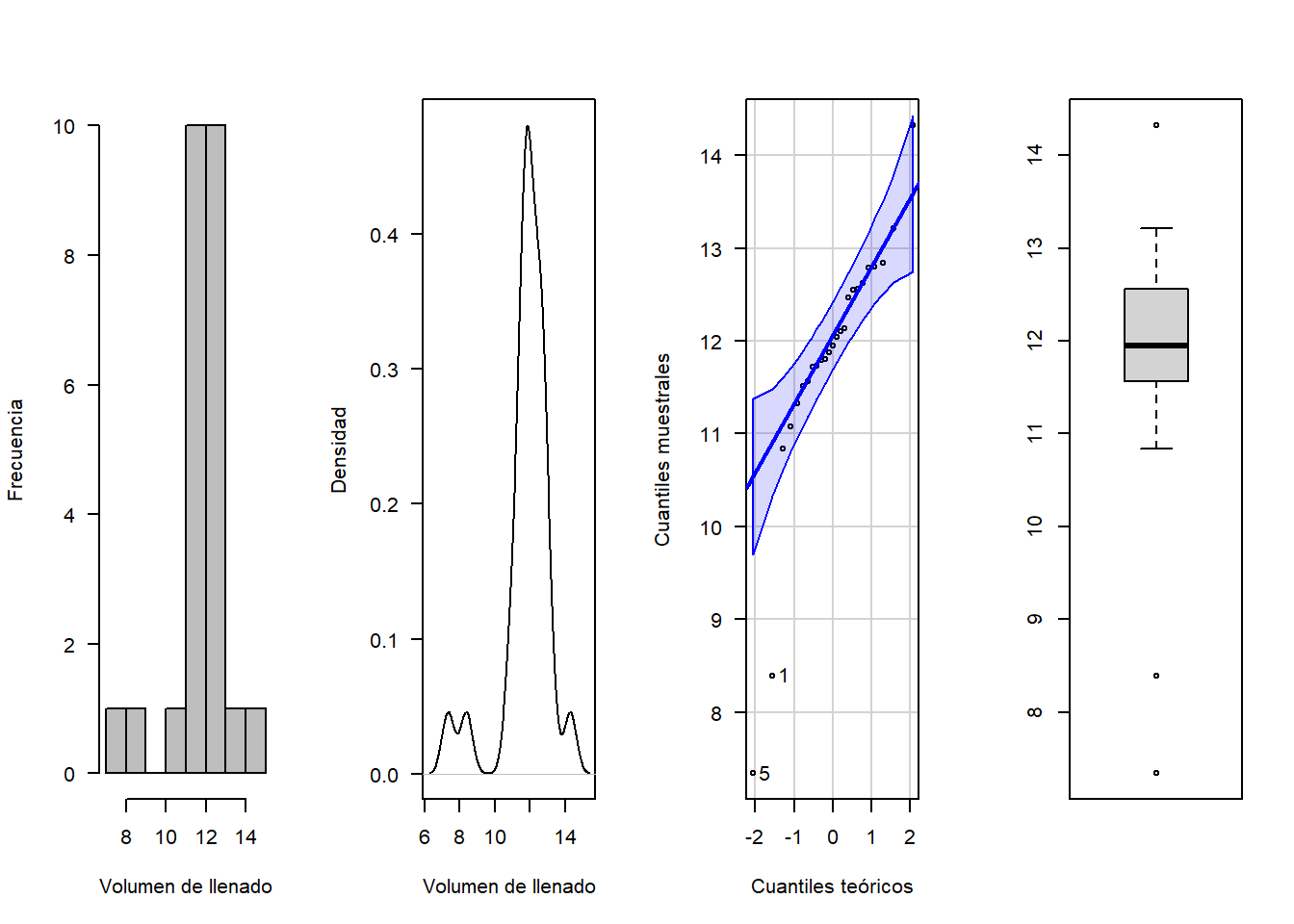
ks.test(volumen, "pnorm", mean =11.81, sd=1.4)##
## Exact one-sample Kolmogorov-Smirnov test
##
## data: volumen
## D = 0.21516, p-value = 0.1703
## alternative hypothesis: two-sidedshapiro.test(volumen)##
## Shapiro-Wilk normality test
##
## data: volumen
## W = 0.8161, p-value = 0.0004272ad.test(volumen)##
## Anderson-Darling normality test
##
## data: volumen
## A = 1.6505, p-value = 0.0002268cvm.test(volumen)##
## Cramer-von Mises normality test
##
## data: volumen
## W = 0.27431, p-value = 0.0005727sf.test(volumen)##
## Shapiro-Francia normality test
##
## data: volumen
## W = 0.79487, p-value = 0.0004128Pruebas para otras distribuciones
Una alternativa a la no normalidad de los datos, es proceder a implementar pruebas no paramétricas, para evaluar si los datos se ajustan a una distribución hipotética.
Pruebas de hipótesis
\(H_0:\) Los datos analizados siguen una distribución M.
\(H_1:\) Los datos analizados no siguen una distribución M
Test de Kolmogorov-Smirnov K-S
Se emplea para saber si una distribución de probabilidad acumulada difiere de una distribución hipotética, por lo general la distribución normal, la uniforme, la de Poisson o la exponencial. Es decir permite contrastar si un conjunto de datos muestrales proviene de un tipo de distribución.
Estadístico
Cuando K-S se aplica para contrastar la hipótesis de normalidad de la población, el estadístico de prueba es la máxima diferencia entre las funciones de distribución de probabilidad muestral y la teórica:
\[D=max|F_n-F_0(x)|\]
Siendo \(F_n(x)\) la función de distribución muestral y \(F_0(x)\) es la función teórica (normal) especificada en la hipotesis nula \(H_0\)
Ejemplo probando la distribución exponencial
Celia quiere medir el tiempo de atención a los usuarios. Se seleccionaron 20 personas y los tiempos de atención en minutos.
require(car)
tiempo<-c(3.69, 39.50, 4.43, 2.70, 9.11, 10.21, 10.44, 2.57, 5.68, 0.80,12.63, 2.35, 25.47, 8.07, 0.96, 0.21, 12.06, 10.79, 6.58, 13.06)
par(mfrow=c(1,4))
hist(tiempo, xlab = "Tiempo", ylab = "Frecuencia", las=1, main = "", col = "gray")
qqPlot(tiempo, col = "gray", ylab="Tiempo")## [1] 2 13plot(density(tiempo), xlab = "Tiempo", ylab = "Densidad", las=1, main = "")
boxplot(tiempo, xlab = "Tiempo", ylab = "Densidad", las=1, main = "")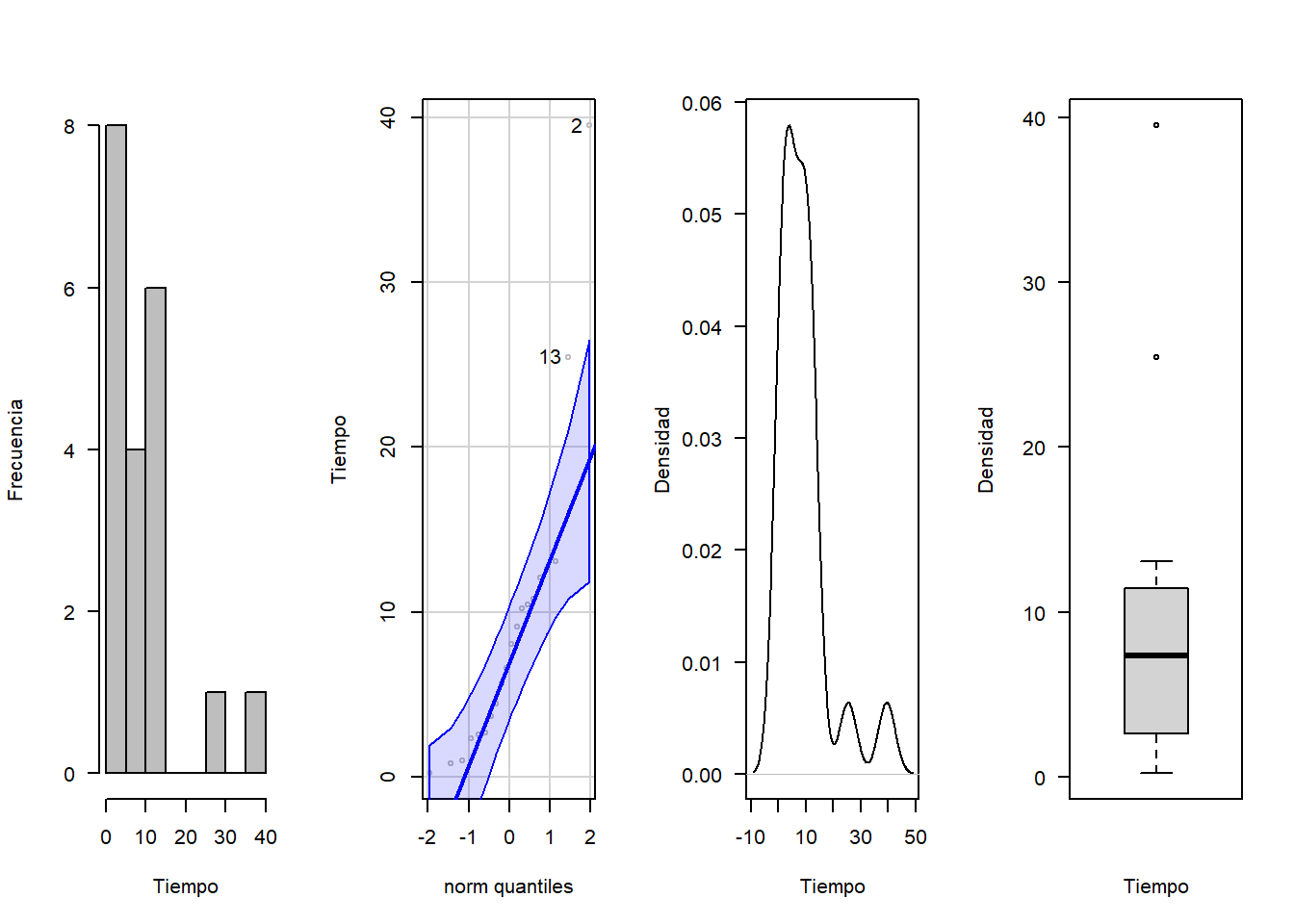
Se procede a revisar el ajuste con respecto a una distribución exponencial con un α=0.05
Sea X el tiempo entre llegadas a Celia Express.
\[H_0:X∼exp\]
\[H_1:X≁exp\]
La siguiente función ayuda a estimar los parámetros del modelo
library(MASS)
Ajustex <- fitdistr(tiempo,"exponential")
Ajustex## rate
## 0.11030831
## (0.02466569)Ks<- ks.test(tiempo, "pexp", rate=Ajustex$estimate[1])
Ks##
## Exact one-sample Kolmogorov-Smirnov test
##
## data: tiempo
## D = 0.13678, p-value = 0.8006
## alternative hypothesis: two-sidedSegún las pruebas realizadas, no se rechaza la hipótesis nula y por tanto, se asume la distribución exponencial.
Ejemplo comparando dos distribuciones
Se desea saber si los datos de potabilidad de agua (potable y no potable) siguen la misma distribución de probabilidad.
\[H_0:X_{si}∼X_{no}\]
\[H_1:X_{si}≁X_{no}\]
par(mfrow=c(1,2))
hist(si)
hist(no)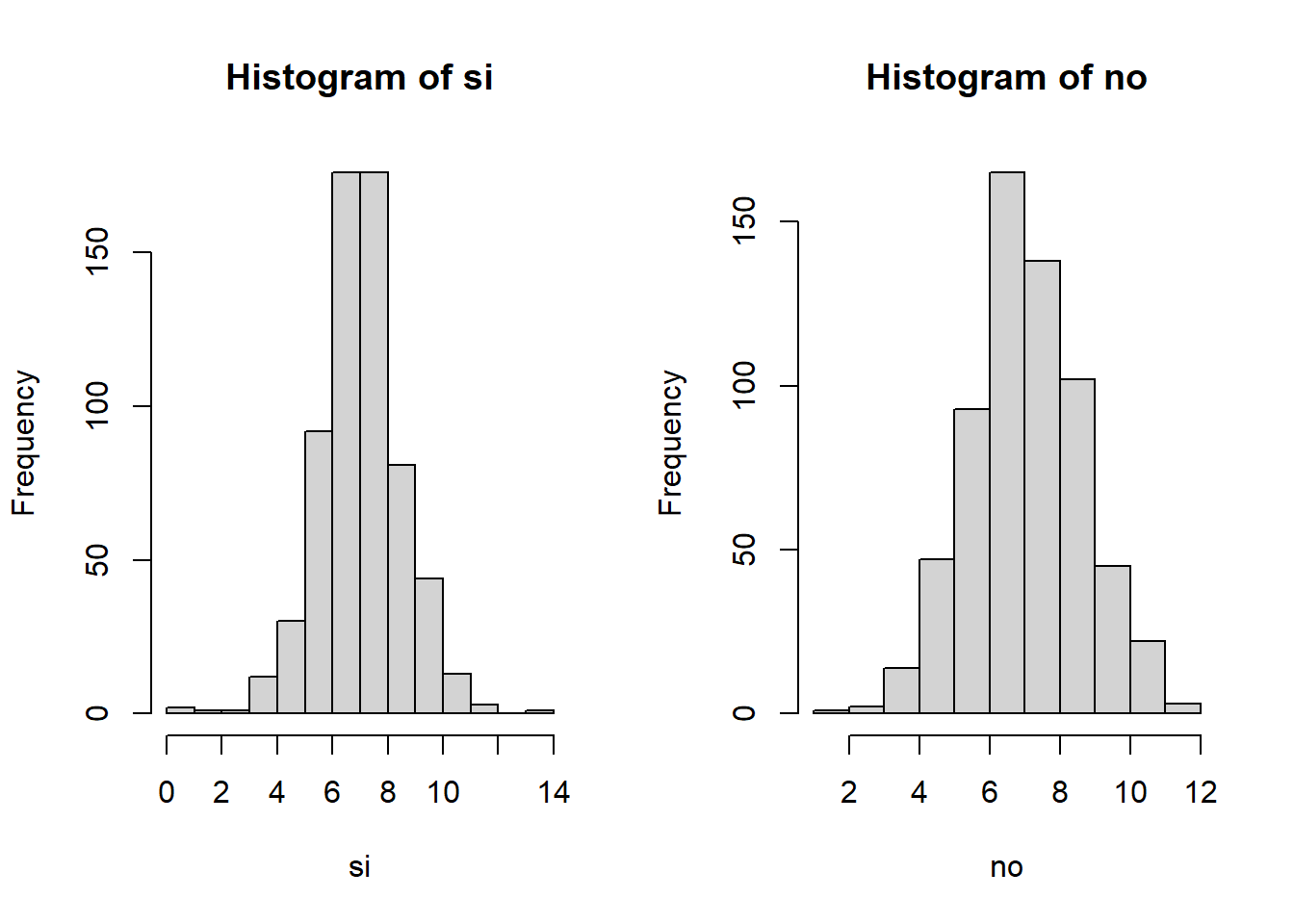
ks.test(si, no)## Warning in ks.test.default(si, no): p-value will be approximate in the presence
## of ties##
## Asymptotic two-sample Kolmogorov-Smirnov test
##
## data: si and no
## D = 0.058544, p-value = 0.2289
## alternative hypothesis: two-sidedEjemplo comparando dos distribuciones
Se desea saber si los datos de potabilidad de agua (potable y no potable) siguen la misma distribución de probabilidad.
\[H_0:X_{si}∼X_{no}\]
\[H_1:X_{si}≁X_{no}\]
par(mfrow=c(1,2))
hist(si)
hist(no)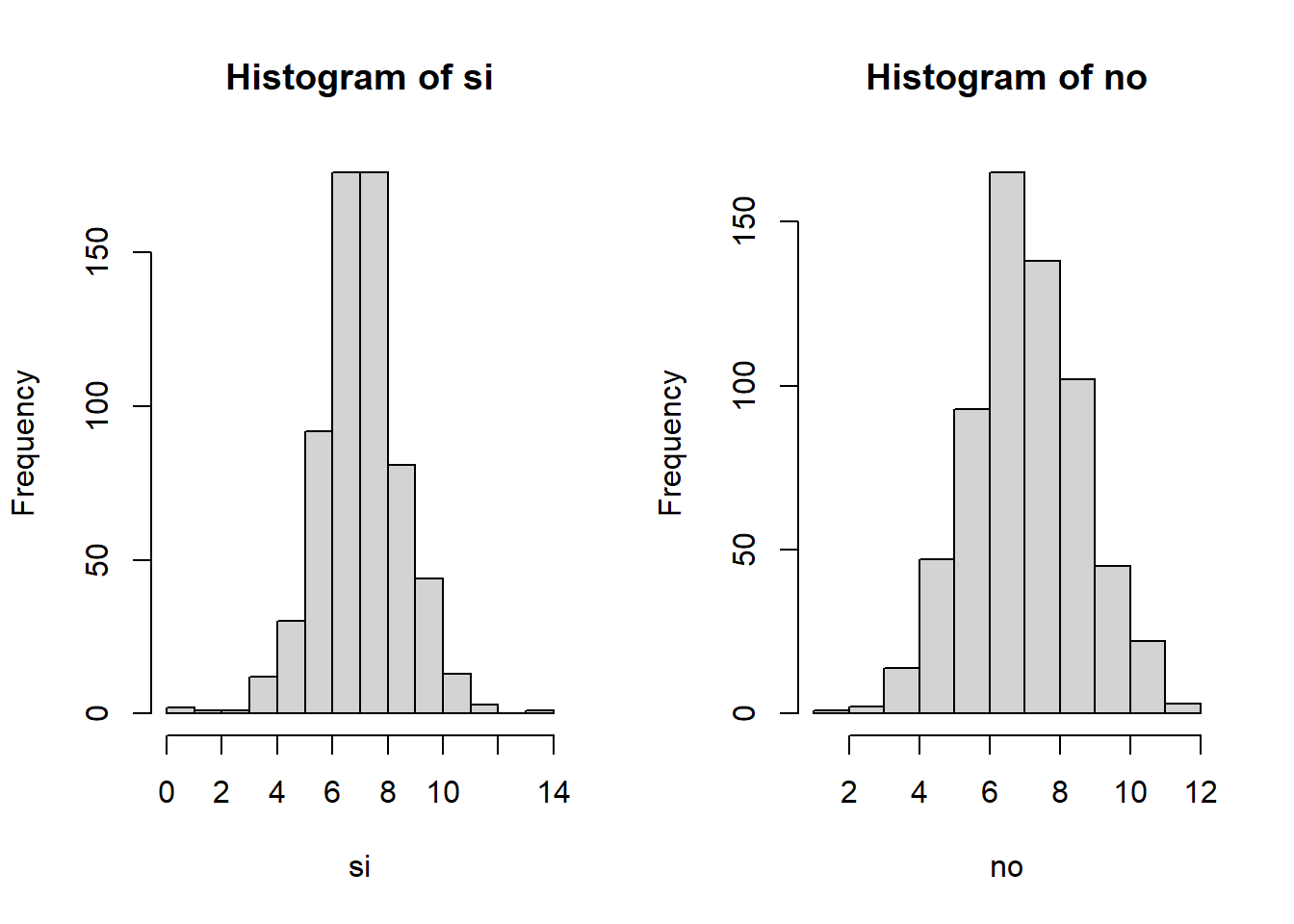
ks.test(si, no)## Warning in ks.test.default(si, no): p-value will be approximate in the presence
## of ties##
## Asymptotic two-sample Kolmogorov-Smirnov test
##
## data: si and no
## D = 0.058544, p-value = 0.2289
## alternative hypothesis: two-sided